乱七八糟的知识点
Jul 10, 2020 · 26 min · machine learning , deep learning , nlp
菜鸡在失学失业的惊慌失措之下的胡乱总结,又因为懒惰压制了惊慌失措所以并没有总结多少…
优化器
损失函数通常为:
无动量
每次迭代按梯度方向更新参数, 是学习率:
BGD
Batch Gradient Descent,批量梯度下降,在每一次迭代时使用所有样本来进行梯度更新:
-
所有的样本都对参数更新有贡献,凸函数假设下一定能达到全局最优;
-
每次迭代都需要对所有样本进行计算,所以样本太多时,要耗费大量计算资源和时间
SGD
Stochastic Gradient Descent,随机梯度下降,每次迭代随机选一个样本 来近似所有样本,并更新梯度:
-
每次参数更新只需要一个样本,速度快
-
计算得到的不是准确梯度,凸函数假设下也不一定有全局最优
MBGD
Mini-Batch Gradient Descent,小批量梯度下降,对 BGD 和 SGD 的折中,每次迭代用 m(batch size)个样本来对参数进行更新:
m 是一个远小于总训练样本数 M 的数,通常为 2 的幂次(以充分利用矩阵运算)。为了避免样本的特定顺序给算法收敛带来的影响,一般会在每个 epoch 随机打乱所有样本,然后每次迭代时按顺序选 m 个样本,直到遍历完所有样本。
-
用一个 batch 来近似整体样本的分布情况,降低了随机梯度的方差,提高了算法稳定性
-
通过矩阵运算,用一个 batch 来优化参数并不会比用单个样本来优化参数慢太多
一阶动量
Polyak’s Momentum
最简单的 momentum,又名 Heavy Ball。引入惯性,即每次更新时,在一定程度上保留之前更新的方向:
是 momentum parameter, 时就相当于原始的梯度下降。 就是 Polyak’s momentum。
-
有一定的摆脱局部最优的能力
-
加快收敛速度。这里是一个数学上的解释:从动力学角度看优化算法:从 SGD 到动量加速。
Nesterov’s Momentum
Nesterov Accelerated Gradient(NAG),先按照之前的更新方向更新一步,然后在该位置计算梯度,再按梯度方向更新:
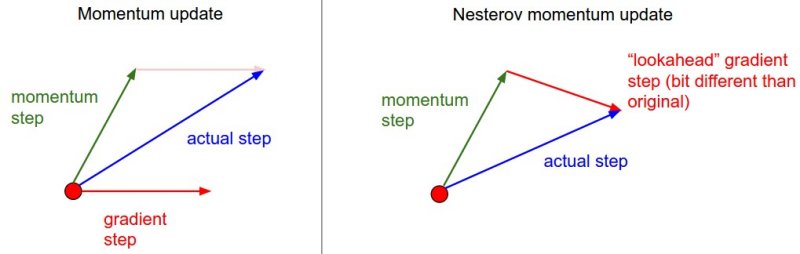
梯度不是根据当前参数位置 ,而是根据先走了本来计划要走的一步后,达到的参数位置 计算出来的。
- 比原始 momentum 收敛得更快,这里是一个解释,简单来说就是因为 NAG 相对于 momentum 多了一个本次梯度相对上次梯度的变化量(目标函数的二阶导)。
二阶动量
AdaGrad
上述方法对于所有参数都用了同一个学习率,但同一个学习率不一定适合所有参数。不是所有神经网络中的参数都会经常被用到,经常更新的参数可能已经到了仅需要微调的阶段,但偶尔更新的参数可能还需要较大幅度的更新。因此 AdaGrad 的思想是给不同的参数不同的学习率。
引入二阶动量,即该维度上,迄今为止所有梯度值的平方和:
是一个用于保证分母非 0 的平滑项。相当于现在学习率是 ,参数更新越频繁,二阶动量就越大,学习率就越小。
-
给不同参数不同的学习率
-
因为 单调递增,所有学习率会单调递减至(接近)0,可能会使训练过程提前结束
RMSProp
为了避免学习率下降过于激进,RMSProp 用了梯度的指数加权移动平均,而不是简单累积所有历史梯度:
多了一个超参数 。可以看到每次累加的梯度的平方项的权重都是 的指数,所以叫指数加权移动平均。只要通过控制 的大小,就可以使每次累加的梯度信息的权重减小不同的程度。越接近当前时刻,梯度权重就越大,影响也就越大;离当前时刻越远,梯度权重越小,影响也就越小。
AdaDelta
二阶动量跟 RMSProp 是一样的:
但没有学习率这个超参数,而是维护了一个能够根据梯度信息自动变化的量 :
如果不考虑 ,可以看做是用 代替了 RMSProp 中的学习率 。
Adam
Adaptive Moment Estimation,考虑了一阶动量和二阶动量,可以理解为 momentum + RMSprop:
初始化:,这个初始化值跟真实值有偏差。而初期的更新幅度会很大,会严重受到初始化偏差的影响,所以有偏差修正(这里是更详细的解释):
偏差修正在初期的影响比较大,后期的影响会越来越小。
最终的参数更新:
参考
词向量
统计方法
one-hot
最简单的词向量。设词典大小为 n,则每个词的向量为一个 n 维向量,向量中其对应位置上的值为 1,其他位置都是 0。
-
维度灾难:特征维度过高导致样本稀疏,造成计算困难
-
语义鸿沟:无法通过词向量之间的距离来反映词之间的相似程度(任意两个向量的距离是相同的)
-
无法反映文本的有序性
为了将语义融入到词表示中,有了分布式假说(distributional hypothesis):词的语义由其上下文决定。后面的词表示方法都是基于分布式假说。
共现矩阵
共现矩阵(Co-occurrence Matrix)是由一个指定大小的窗口内的单词共现次数构成的矩阵,如对于以下语料:
- I like deep learning.
- I like NLP.
- I enjoy flying.
当窗口大小为 3(左右长度都为 1)时,共现矩阵为:
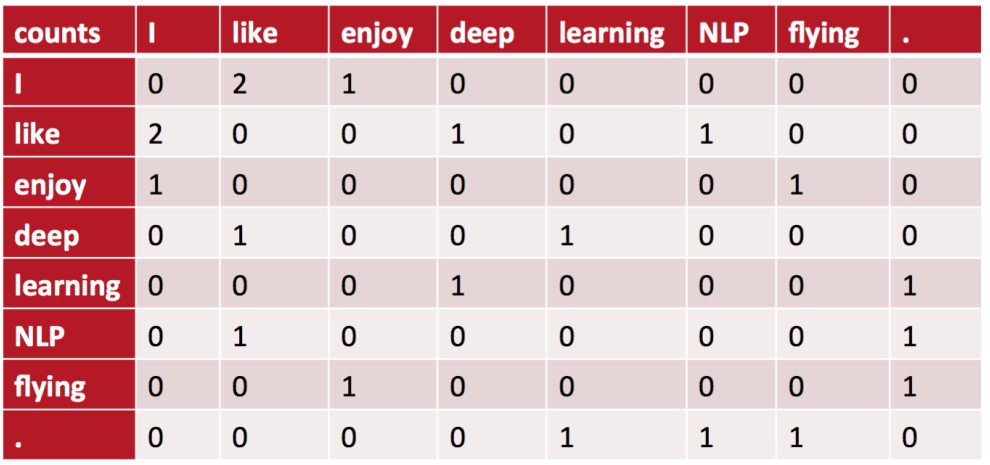
可以想到的方法是把共现矩阵的行或列作为单词的词向量:
-
能够在一定程度上表现单词之间的语义关系,相比 one-hot 有了一定的提升
-
没有解决维度灾难问题
SVD
SVD(Singular Value Decomposition,奇异值分解)的思想是对共现矩阵中得到的词向量进行降维,从而得到一个稠密的连续词向量。
奇异值分解可以对任意大小的矩阵 进行分解:
其中,;,各个向量相互正交,被称为左奇异矩阵;,仅在对角线上有值,被称为奇异值;,各个向量也相互正交,被称为右奇异矩阵。具体分解原理可以参考这里。
奇异值是从大到小排列的,可以认为奇异值代表了特征的权重。通常前 10% 甚至 1% 的奇异值的和就占了所有奇异值和的 99% 以上,所以一般会选择用 的前 维来代表词向量矩阵,最终词向量矩阵大小为 , 为词典大小, 为词向量维度。
-
能够在一定程度上表现单词之间的语义关系
-
利用了全局语料特征
-
矩阵过于稀疏,因为在构建共现矩阵时,有很多词是没有共现的
-
矩阵分解复杂度高
-
需要手动去除高频无意义的停用词(如 is、a 等),否则会影响共现矩阵分解的效果
浅层词嵌入
通常采用浅层网络进行训练(浅层词嵌入,Non-Contextual Embeddings),主要缺陷为:
-
词向量与上下文无关,每个单词的词向量始终是相同的(静态),无法解决一词多义问题
-
OOV(Out of Vocabulary)问题。一种解决方法是引入字符级(CharCNN)或 subword(fastText)表示
NNLM
A Neural Probabilistic Language Model. Bengio, Yoshua, et al. Journal of Machine Learning Research. [Paper]
NNLM(Neural Network Language Model,神经网络语言模型)即用神经网络训练得到一个语言模型,同时产生副产物词向量。其思想为:
-
假定词典中的每个单词都对应一个连续的特征向量
-
假定一个连续平滑的概率模型,输入为前 n-1 个单词的词向量,输出为一个维度为词表大小的向量,代表每个词出现的概率
-
同时学习词向量的权重和 n 元组(ngram)模型里的参数
其主要计算量在隐藏层上。softmax 层也是一个计算瓶颈,因为需要对词典中所有词都计算一遍条件概率。
-
词向量只是一个副产物,由于其巨大的参数空间,NNLM 的训练很慢
-
使用的是全连接神经网络,因此只能处理定长序列(不过后来的 RNNLM 解决了这个问题)
word2vec
Efficient Estimation of Word Representations in Vector Space. Tomas Mikolov, et al. ICLR 2013. [Paper]
Distributed Representations of Words and Phrases and their Compositionality. Tomas Mikolov, et al. NIPS 2013. [Paper]
具体原理和数学推导可以参考这里:word2vec 中的数学原理详解
word2vec 的本质依然是语言模型,但是它的目标并不是语言模型本身,而是词向量。所以它所采取的一系列优化都是为了更快更好的得到词向量。
两种模型
CBOW
利用给定上下文 (单词 的前后共 个词)预测单词 ,目标函数为( 为语料库):
Skip-gram
利用给定单词 来预测上下文 ,目标函数为:
两个优化方法
Hierarchical Softmax
Hierarchical Softmax(层次化 Softmax)会先构造一个哈夫曼树(Huffman Coding),然后将复杂的归一化概率问题转化为一系列二分类的条件概率相乘的形式,从而将目标概率的计算复杂度从 降到 , 为词典大小。
哈夫曼树又称为最优二叉树,表示一种带权路径长度最短的二叉树。带权路径长度:叶子结点的权值 * 该结点到根结点的路径长度。
这里构造的哈夫曼树的根节点是整个词典,每一个子节点为父节点的两个不相交子集,每个单词都是一个叶子节点,叶子节点的权值为词频。带权路径最小的条件保证了哈夫曼树中,高频词离根结点更近,而低频词离根结点更远。
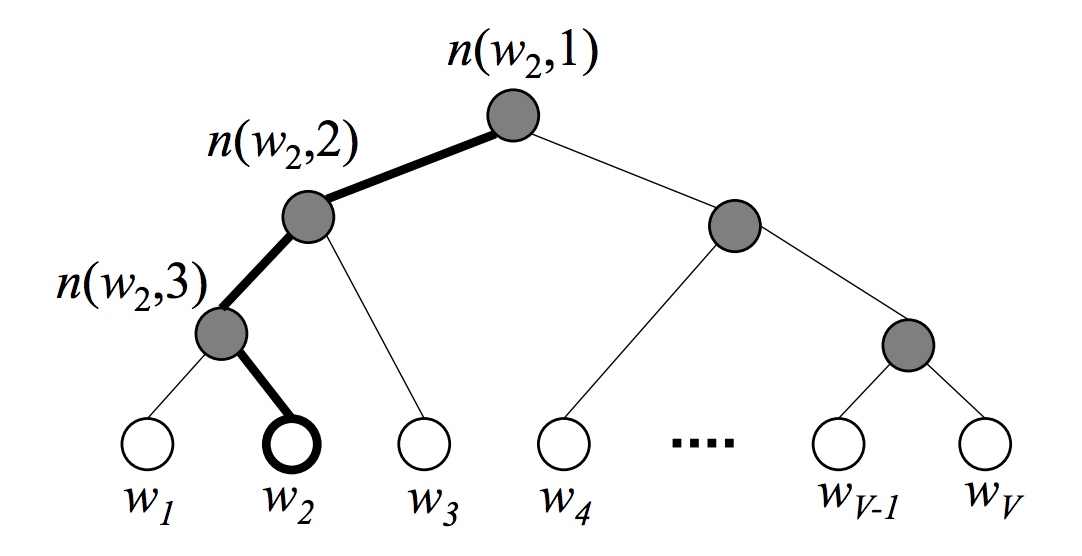
考虑单词 对应的叶子节点,记:
-
:从根节点到 对应的叶子节点的路径
-
:路径 中包含的节点个数
-
:词 的哈夫曼编码,共 位(根节点不对应编码), 表示路径 中第 个节点对应的编码
-
: 表示路径 中第 个非叶子结点的对应的向量,作为求条件概率的参数
假设根结点为词典 ,则第二层的两个子节点分别为 的两个子集 和 。左子节点的哈夫曼编码为 0(负类),右子节点为 1(正类)。
CBOW
则在给定上下文的情况下,由二分类逻辑回归可知,第 个节点被分为正类(即 )的概率为:
分为负类(即 )的概率为:
其中, 为相加后的上下文词向量。最终的条件概率为:
Skip-gram
条件概率函数为:
其中 是单词 的词向量。
然后对条件概率函数求最大似然即可,具体公式上面引用的那篇博客里有。
-
时间复杂度从 降到
-
人为增强了词与词之间的耦合性。如果一个词的条件概率出现变化,会影响到其路径上所有非叶节点的概率变化,间接地对其他词的条件概率造成影响。所以构造合适的二叉树非常重要。
Negative Sampling
Negative-Sampling(NEG,负采样)可以作为 Hierarchical Softmax 的一种替代,它不再使用哈夫曼树,而是使用相对简单的随机负采样。
CBOW
对于给定的 ,单词 是一个正样本,其他词都是负样本。我们希望最大化:
其中 是采样出的关于 的负样本子集。把上面两个式子合起来可以得到:
其中, 为预测中心词为 的概率, 为预测中心词为 的概率。因此最大化 就相当于最大化 (正样本概率),同时最小化所有的 (负样本概率)。
目标函数为:
Skip-gram
目标函数为:
其中:
负采样算法
需要采样出负样本子集 。负采样算法是一个带权采样过程,即高频词被选为负样本的概率应该比较大,而低频词被选中的概率应该比较小。
设词典 中每一个单词 对应一个线段 ,长度为:
然后把这些线段首尾相接拼在一起,形成一个长度为 1 的线段(相当于对区间 做非等距切分)。然后再引入一个区间 上的 等距切分,其中 (word2vec 源码中 )。然后即可建立这两个切分的映射关系,如下图所示:
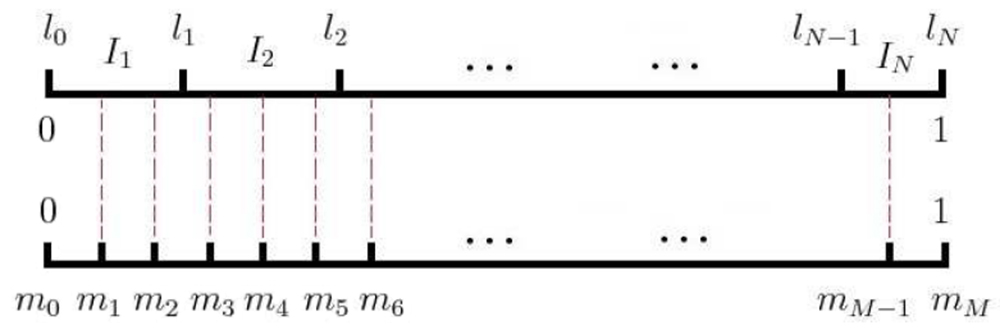
采样时,每次生成一个 之间的整数 ,则 对应的线段对应的单词就是一个样本。当碰巧采样到自己(正样本)时,则跳过。
特点
-
为了提高计算效率,将词向量直接相加(NNLM 中是把词向量拼接)
-
舍弃了 NNLM 中的隐层,只有一个投影层(用于累加词向量)
-
真正考虑了上下文(NNLM 的输入严格来说只有上文)
-
hierarchical softmax 和 negative sampling 优化
-
只用了局部语料(特征提取基于滑窗)
GloVe
GloVe: Global Vectors for Word Representation. Jeffrey Pennington, et al. EMNLP 2014. [Paper]
GloVe(Global Vectors for Word Representation)可以看做是 SVD 和 word2vec 的结合,它先构建一个共现矩阵 ,矩阵中的元素 为单词 和上下文单词 在指定大小的上下文窗口中共同出现的次数。
然后构建词向量和共现矩阵之间的近似关系,目标函数为:
这两篇博客推导了目标函数是怎么来的:理解 GloVe 模型、GloVe 详解。
可以认为它的 label 是 。 和 是两个不同的词向量,因为共现矩阵 是对称的,所以理论上 和 也应该是对称的,但它们初始化的值不一样,所以最终的结果也不一样。为了提高鲁棒性,会用 作为最终的词向量。
这个目标函数就是一个均方差损失(Mean Square Error,MSE),只不过基于出现频率越高的词对权重应该越大的原则,还加了一个权重函数 (论文里 取 ):
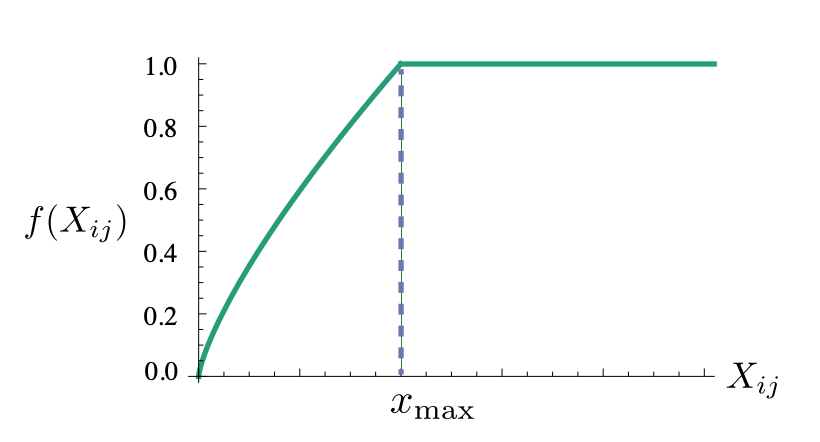
该函数满足以下条件:
-
非减函数
-
到达一定程度之后不再增加(因为不希望权重过大)
-
如果两个单词没有在一起出现,即 ,那么他们应该不参与到损失函数的计算中,所以需要有
GloVe 的特点:
-
相比 SVD,GloVe 时间复杂度更低
-
相比 word2vec,GloVe 用了全局语料,需要事先统计共现概率
-
word2vec 的损失函数是带权重的交叉熵,GloVe 的损失函数是带权重的均方差损失
fastText
模型结构与 CBOW 一样。
用于计算词向量时:
-
无监督
-
局部语料
-
相比 CBOW,考虑了 subword,最终的词向量是 subword 向量和的叠加。这样做的优点:
-
对于低频词生成的词向量效果会更好,因为它们的 subword 可以和其它词共享
-
对于训练集之外的单词,依然可以构建它们的词向量(叠加它们的 subword 向量)
-
用于文本分类时:
-
有监督,预测句子的类别标签
-
引入 ngrams,考虑词序特征
-
引入 subword 来处理长词、未登陆词
-
hierarchical softmax 优化,对输出的分类标签建立哈夫曼树,样本中标签多的类别离根节点更近
预训练编码器
通过一个能够输出上下文相关的词向量的预训练编码器来解决一词多义的问题。这类预训练编码器输出的向量被称为「上下文相关的词嵌入(contextual word embeddings)」。
主要代表有 ELMo、GPT、BERT、XLNet 等,总结在预训练模型一节。
参考
-
语言模型综述:A Survey on Neural Network Language Models
中文翻译:神经网络语言模型综述
-
预训练模型综述:Pre-trained Models for Natural Language Processing: A Survey
预训练模型
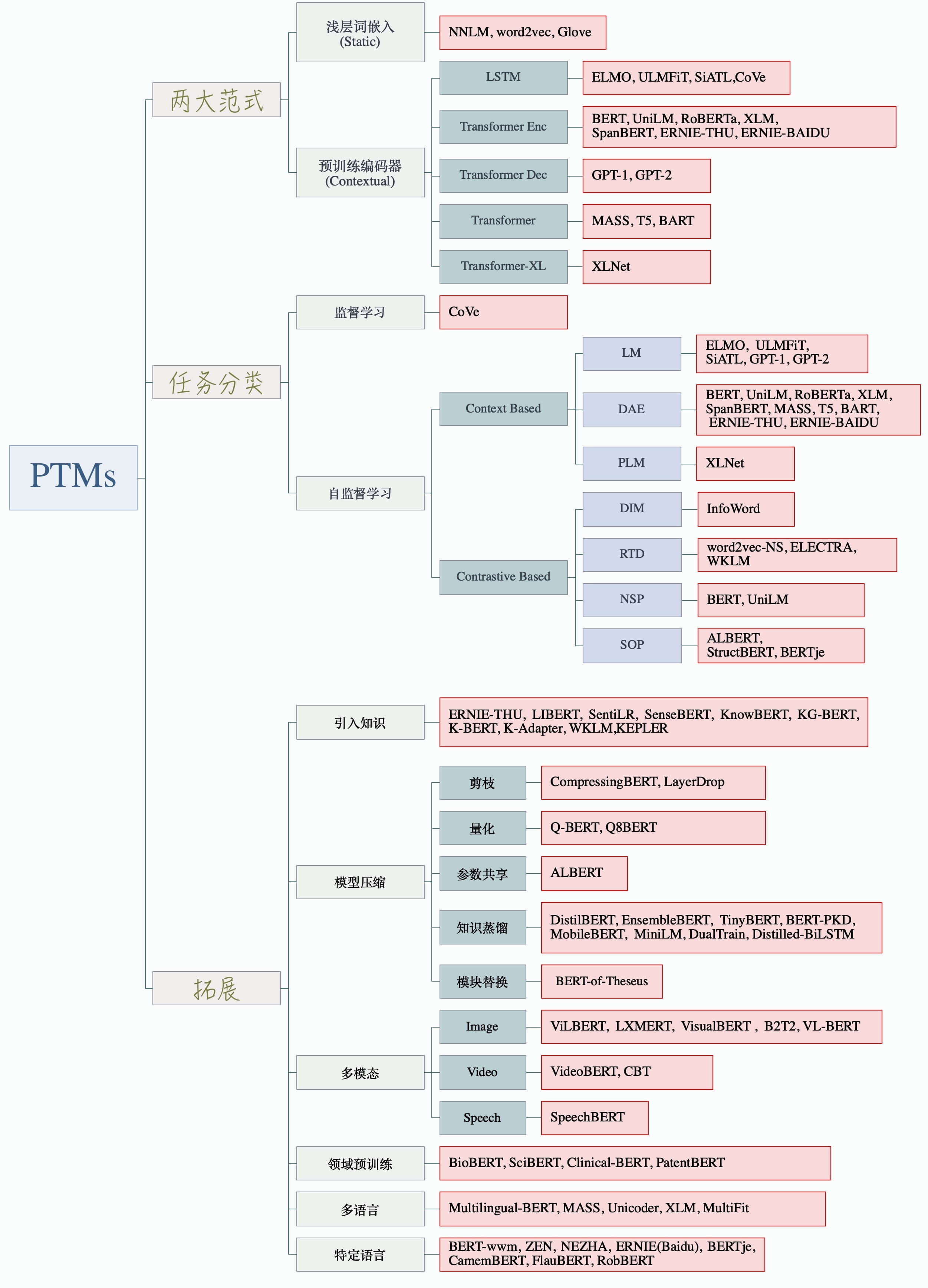
预训练模型(Pre-trained Models)会学习带有上下文的 contextual embedding,词的表征可以根据上下的语境而动态改变。给定一个文本序列 , 的 contextual embedding(或者叫 dynamical embedding) 依赖于整个文本:
就是下图中的 contextual encoder:
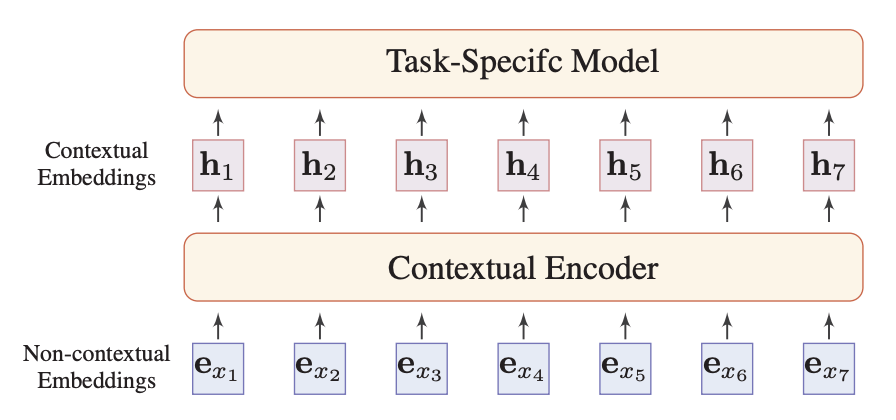
输入为文本序列的 one-hot 编码,经过 embedding 层得到 non-contextual embeddings,然后经过 contextual encoder 得到 contextual embeddings。embedding 层和 contextual encoder 都需要学习。
绝大多数预训练模型用的是自监督学习,这篇综述把基于自监督学习的预训练模型分为了两类:基于上下文(Context Based)和基于对比(Contrastive Based)。而基于上下文的预训练模型所用的语言模型可以分为:
-
自回归语言模型(Aotoregressive Lanuage Modeling)
依据前面(或后面)出现的 token 来预测当前时刻的 token,代表模型有 ELMo、GTP 等。
特点:
-
语言模型联合概率的无偏估计(即传统的语言模型),考虑被预测 token 之间的相关性,天然适合处理生成任务(所以 GPT 能编故事,BERT 编不太了)
-
只能获取单方向的信息
-
-
自编码语言模型(Autoencoding Language Modeling)
通过上下文信息来预测当前被 mask 的 token,代表模型有 BERT 等。
其中 为上下文,即加噪后的文本序列;如果当前 token 需要被预测,,否则 。
特点:
-
通过引入噪声「MASK」来获取双向上下文信息表示
-
引入独立性假设,为语言模型联合概率的有偏估计,没有考虑预测 token 之间的相关性
-
预训练(DAE;有「MASK」)与微调(Autogressive LM;,无「MASK」)模式不匹配
-
-
排列语言模型(Permuted Language Model)
ELMo
Deep contextualized word representations. Matthew E. Peters, et al. NAACL-HLT 2018. [Paper] [Code]
自回归语言模型。编码器是双层双向 LSTM,每层的两个单向 LSTM(前向和后向)直接拼接。并未进行双向信息的融合,所以不会出现标签泄漏。(这里是对标签泄漏的更详细的解释)
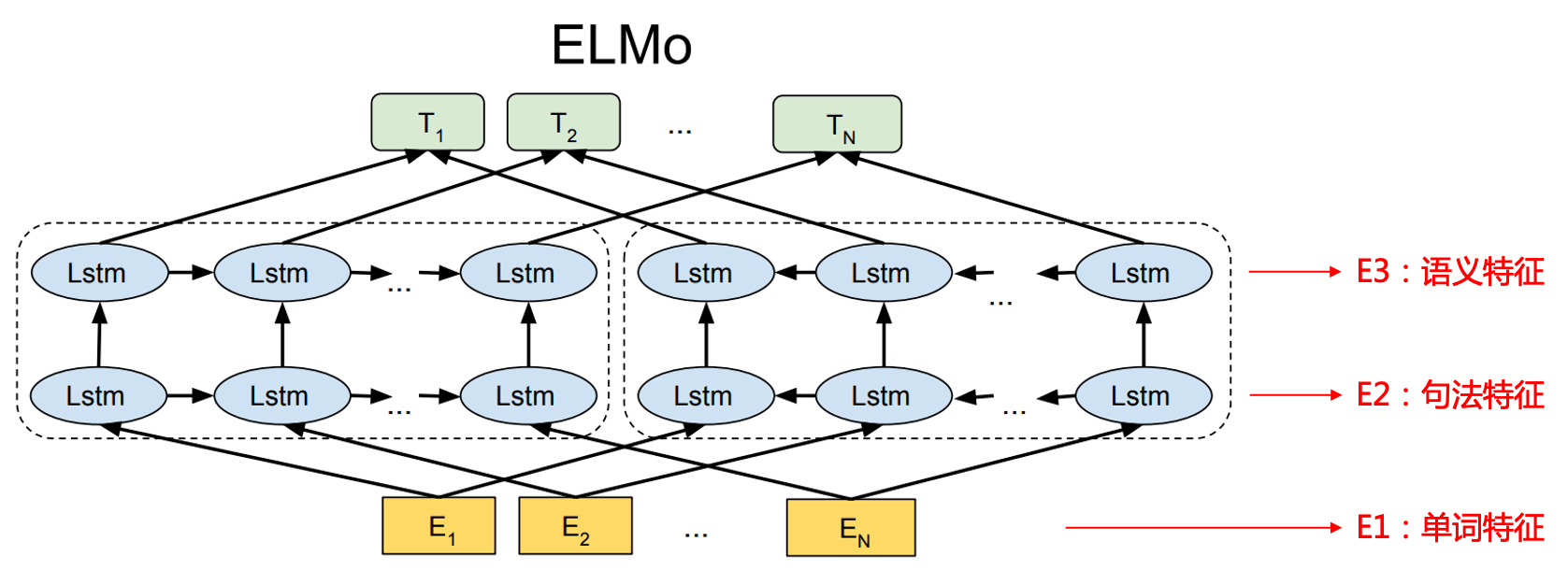
ELMo 中每一层的输出向量都有不同的含义:E1 是单词特征,E2 是句法特征,E3 是语义特征。下游任务在使用词向量时,会通过一些方式将每一层的向量融合得到预训练词向量,然后将该向量与下游任务的词向量进行拼接得到最终的词向量。
GPT-1
Improving Language Understanding by Generative Pre-Training. Alec Radford, et al. [Paper] [Code]
自回归语言模型。编码器是 Transformer 的 decoder 部分(首次将 Transformer 应用于预训练语言模型),decoder 部分只能使用单向信息,即只使用上文预测当前词,无法获取上下文相关的特征表示。
相比 ELMo:
-
编码器从 BiLSTM 变成 Transformer
-
只用上文信息而不使用下文
-
进行下游任务时,直接在预训练模型上进行 fine-tuning,而不是直接用现成的词向量
BERT
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Jacob Devlin, et al. NAACL-HLT 2019. [Paper] [Slide] [Code]
自编码语言模型。编码器是 Transformer 的 encoder 部分,更够利用双向信息。
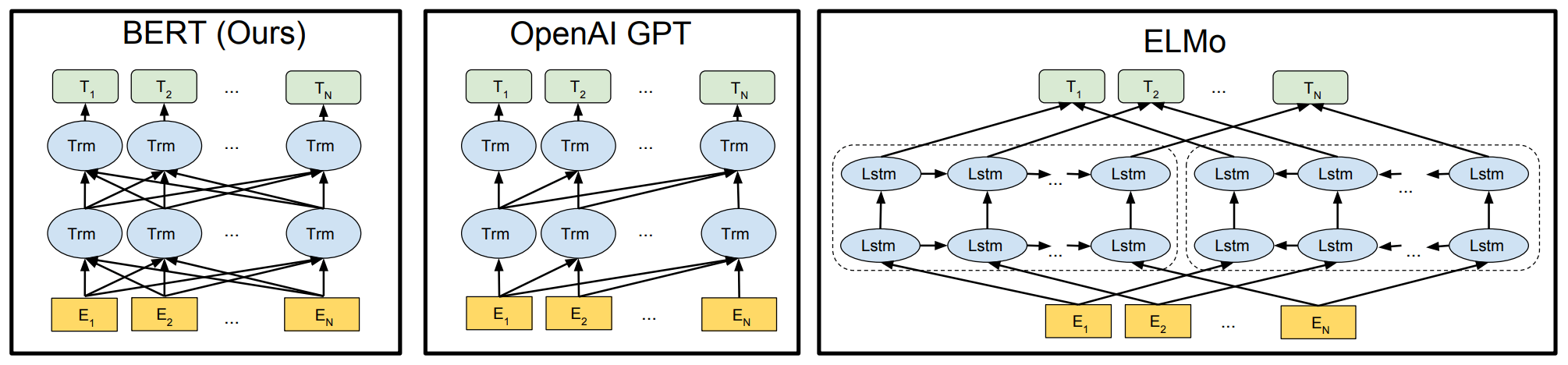
BERT 还在 Transformer-Encoder 的基础上做了 mask 操作(Masked Language Model,MLM),即随机 mask 掉输入序列的部分 tokens,然后只预测被 mask 掉的 tokens。MLM 能够更好的获取双向上下文特征表示,也能解决深度 Transformer 带来的标签泄露(see itself)的问题。标签泄露指,Transformer 自带的全局 self-attention 会将上下文的词编码到当前模型里,所以在预测其他词的时候,该词的信息已经包含在了前一层的网络参数里:
BERT 的特点:
-
能够获取上下文相关的双向特征表示
-
在生成任务上表现不佳:预训练(DAE;有「MASK」标记)与微调(Autogressive LM;无「MASK」标记)模式不匹配
-
引入了独立性假设,为语言模型联合概率的有偏估计,没有考虑预测「MASK」之间的相关性
XLNet
XLNet: Generalized Autoregressive Pretraining for Language Understanding. Zhilin Yang, et al. NIPS 2019. [Paper] [Code]
参考
-
语言模型综述:A Survey on Neural Network Language Models
中文翻译:神经网络语言模型综述
-
预训练模型综述:Pre-trained Models for Natural Language Processing: A Survey
Batch Normalization
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. Sergey Ioffe and Christian Szegedy. ICML 2015. [Paper]
Inception V2 的论文,重要贡献之一是提出了 Batch Normalization(BN,批标准化)。