看过的关于机器翻译 / 文本摘要 / 图像描述的论文的总结,到时候大概也可以直接复制粘贴进毕业论文里。
Machine Translation
给定源语言句子 x,目标是最大化其对应的目标语言翻译 y 的概率,即:
y^=argymaxp(y∣x)
Seq2Seq
Sequence to Sequence Learning with Neural Networks. Ilya Sutskeve, Oriol Vinyals and Quoc V. Le. NIPS 2014. [Paper]
提出了 Sequence to Sequence 框架,由一个 encoder 和一个 decoder 组成。
Encoder
一个 LSTM,用于把源语言句子 x=(x1,...,xTx) 编码成一个固定长度的向量 c:
ht=f1(xt,ht−1)
c=hTx
即 LSTM 最后一个时间步输出的隐状态就是句子编码后的向量。<EOS> 是终止符,不用编码。
Decoder
一个 LSTM,用于生成目标语言翻译 y=(y1,...,yTy),第一个时间步的输入是 c,生成终止符 <EOS> 后停止句子生成。
把上述联合概率用链式法则分解后得到:
p(y)=t=1∏Tp(yt∣{y1,...,yt−1},c)
每个时间步的条件概率为:
p(yt∣{y1,...,yt−1},c)=g(yt−1,st,c)
si=f2(si−1,yi−1)
g 是一个非线性函数,用于输出单词 yt 的概率(比如 softmax),st 是 LSTM(decoder)在 t 时刻的隐状态。
Seq2Seq + Attention
Neural Machine Translation by Jointly Learning to Align and Translate. Dzmitry Bahdanau, Kyunghyun Cho and Yoshua Bengio. ICLR 2015. [arXiv]
首次把 attention 引入 seq2seq。
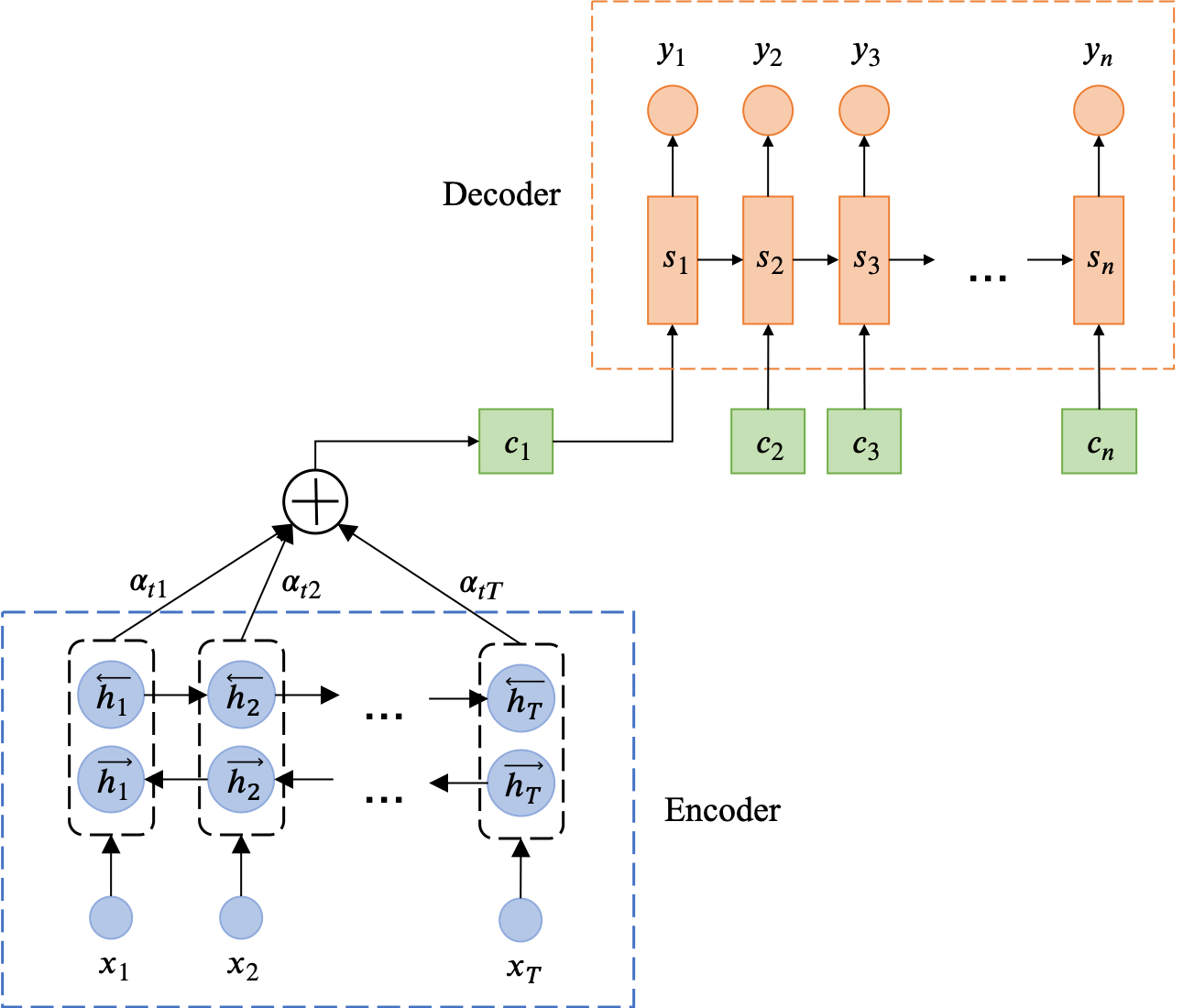
Encoder
encoder 是一个 BiLSTM,即有两个 LSTM:
-
第一个把源句子正向输入(x1→xTx),所有时间步输出的隐状态为 (h1,...,hTx)
-
第二个把源句子逆向输入(xTx→x1),所有时间步输出的隐状态为 (h1,...,hTx)
最终,encoder 每个时间步的输出就是把 hj 和 hj 拼起来:
hj=[hj;hj]
所有时间步的输出为:
(h1,...,hTx)
Decoder
把每个时间步的条件概率定义为:
p(yi∣y1,...,yi−1,x)=g(yi−1,si,ci)
si 是 LSTM 在 i 时刻的隐状态:
si=f(si−1,yi−1,ci)
ci 是 i 时刻的 context vector,通过把 encoder 每个时间步的输出向量加权平均得到:
ci=j=1∑Txαijhj
αij 是 hj 的权重,计算公式为:
eij=a(si−1,hj)
αij=∑k=1Txexp(eik)exp(eij)
a 是一个 MLP,αij 由 eij 归一化(softmax)后得到。相当于 αij 代表了在生成第 i 个目标句子单词时,第 j 个源句子单词的重要性。
Unsupervised NMT
Unsupervised Neural Machine Translation. Mikel Artetxe, et al. ICLR 2018. [arXiv] [Code]
Unsupervised Machine Translation Using Monolingual Corpora Only. Guillaume Lample, et al. ICLR 2018. [Paper]
Text Classification
Hierarchical Attention Network
Hierarchical Attention Networks for Document Classification. Zichao Yang, et al. NAACL 2016. [Paper]
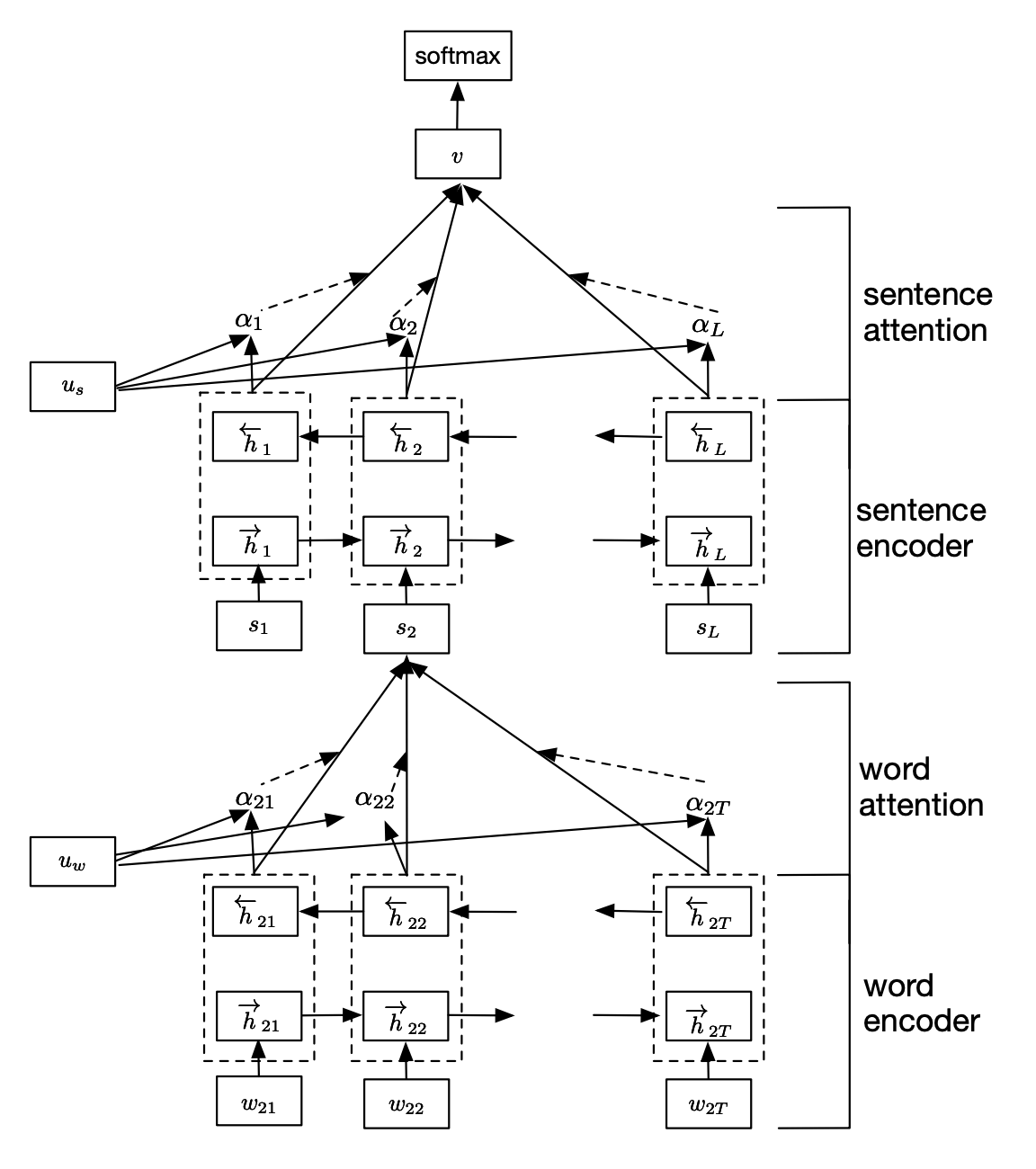
Word Encoder
双向 GRU:
hit=GRU(xit),t∈[1,T]
hit=GRU(xit),t∈[T,1]
hit=[hit;hit]
xij=Wewij 是文档中第 i 个句子的第 t 个单词的词嵌入向量,T 为该句子中的单词个数。
Word Attention
对每个 hit 计算一个权重(MLP + softmax),然后加权平均得到句子向量 si:
uit=tanh(Wwhit+bw)
αit=∑texp(uit⊤uw)exp(uit⊤uw)
si=t∑αithit
softmax 中,uw 是一个随机初始化的 context vector,用于表示哪些词更重要。
Sentence Encoder
依然是双向 GRU,只不过输入为上一步得到的句子向量 si:
hi=GRU(si),t∈[1,L]
hi=GRU(si),t∈[L,1]
hi=[hi;hi]
其中,L 为文档中的句子个数。
Sentence Attention
对每个 hi 计算一个权重(MLP + softmax),然后加权平均得到文档向量 v:
ui=tanh(Wshi+bs)
αit=∑texp(ui⊤us)exp(ui⊤us)
v=t∑αihi
us 依然是是一个随机初始化的 context vector,用于表示哪些句子更重要。
Document Classification
最后把文档向量 v 扔进 softmax 来进行分类:
p=softmax(Wcv+bc)
损失函数为:
L=−d∑logpdj
pdj 是文档 d 的真实标签 j 出现的概率。
Image Captioning
Show and Tell
Show and Tell: A Neural Image Caption Generator. Oriol Vinyals, et al. CVPR 2015. [Paper] [Code]
Google 出品,算是最早开用 CNN-LSTM 做 Image Captioning 这个坑的论文之一。
P.S. 依然是在 CVPR 2015 上,Stanford 也发了篇模型核心结构差不多的论文:
Deep Visual-semantic Alignments for Generating Image Descriptions. Andrej Karpathy and Li Fei-Fei. CVPR 2015. [Paper] [NeuralTalk] [NeuralTalk2]
但鉴于 NeuralTalk 的代码是用 Lua 和 Torch 写的,而我不会 Lua 和 Torch(…),所以这篇论文就没认真看…
CNN-LSTM
模型目标:
θ∗=argθmax(I,S)∑logp(S∣I;θ)
θ 是模型参数,I 是图像,S 是对应的正确的图像描述。也就是要最大化正确描述的概率。
为了解决解决 S 的长度不定的问题,用条件概率的链式法则来把上述联合概率分解成以下形式,这里为了方便扔掉了模型参数 θ:
logp(S∣I)=t=0∑Nlogp(St∣I,S0,...,St−1)
S0 是起始符,SN 是终止符。如果生成了终止符,则该句子生成结束。
LSTM:
在 LSTM 中,每个时间步的条件概率可以表示为:
logp(St∣S1,...,St−1,I)=k(ht,zt)
k 是一个非线性函数,输出为单词 St 的概率。ht 是 LSTM 在当前时间步的隐状态。zt 是图像特征,在这里是 CNN 最后一个全连接层输出的一个向量;在加了 Attention 机制的 LSTM 中则是每个时间步对 CNN 最后一个卷积层输出的特征图进行 Attention 操作后得到的一个向量,依赖于 ht。
新的 xt 输入后,隐状态更新的公式为:
ht=f(xt,ht−1,ct−1)
ct−1 是 LSTM 在上一时间步的细胞状态。
CNN:
用来提图像特征的 CNN 直接用了 Inception V3:
Rethinking the Inception Architecture for Computer Vision. Christian Szegedy, et al. CVPR 2016. [Paper] [Code]
LSTM
在另一篇文章里理过 LSTM。
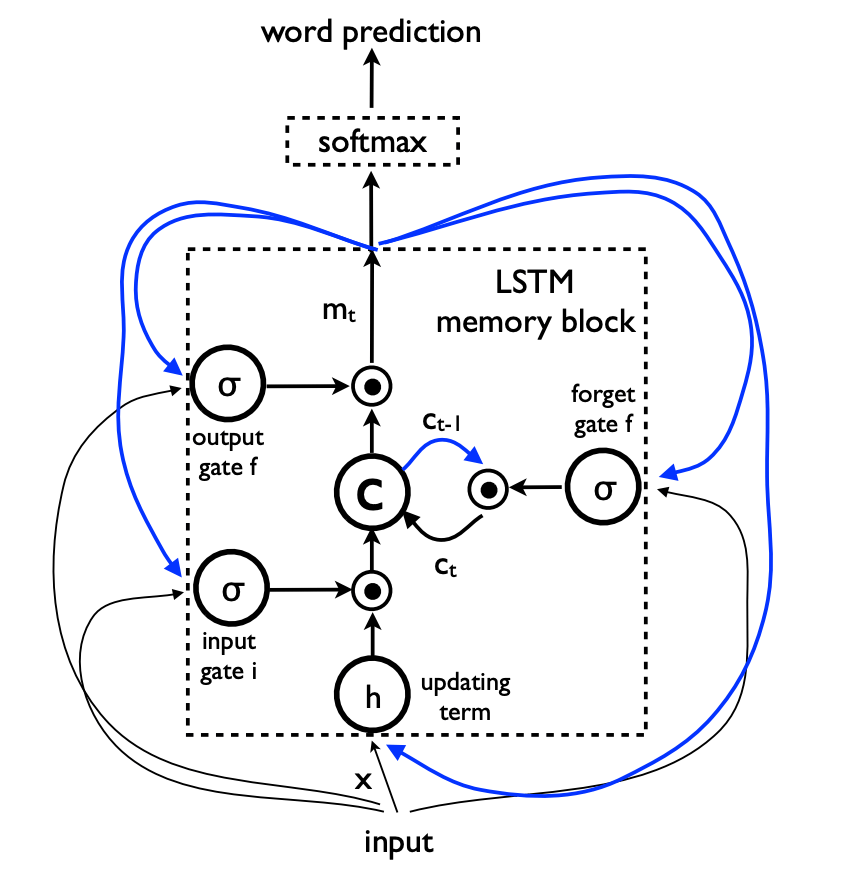
Training
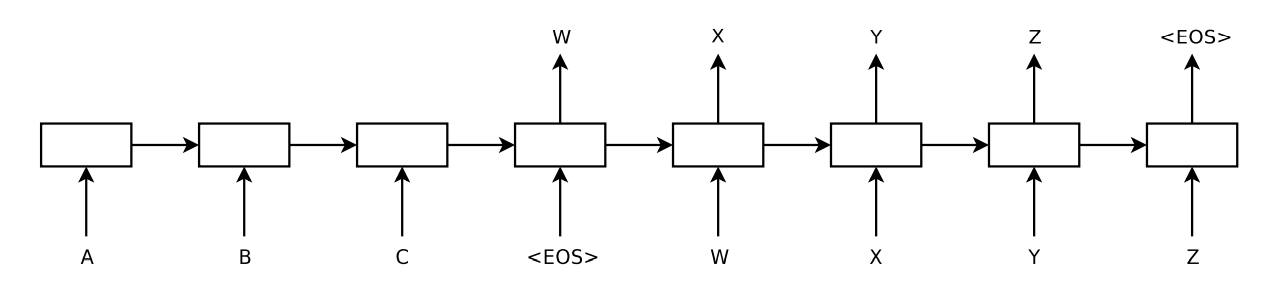
把 LSTM 按时间步展开就是这个样子:
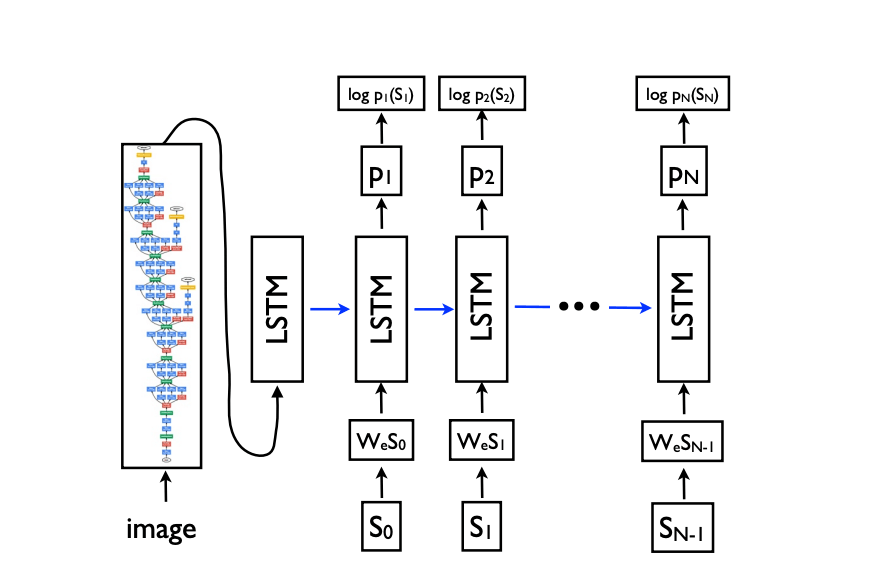
这样看起来就像一个前馈网络了。
假设输入的图片为 I,它的正确描述为 S=(S0,...,SN),则展开过程为:
x−1=CNN(I)
xt=WeSt,t∈{0...N−1}
pt+1=LSTM(xt),t∈{0...N−1}
其中,St 是经过独热编码的单词,都是 1×D 的向量,D 是词典大小;We 是 word embedding;pt 是每个时间步输出的所有单词的概率分布。
图片 I 只在 t=−1 时输入一次,因为论文经过实验后发现如果每个时间步都输入一遍图像,模型会更容易过拟合和学习到图像的噪声。(这里复现了这种做法)
损失函数:
L(I,S)=−t=1∑Nlogpt(St)
目标是通过调 CNN、LSTM 和 We 的参数让 Loss 最小。
训练细节:
- 用在 ImageNet 上训练好的预训练模型来初始化 CNN 参数,效果提升明显;
- 用在一个新闻语料库上训练好的预训练模型来初始化 We 参数,效果提升不明显;
- 尝试 dropout 和 ensembling,效果提升了一些;
- 调 LSTM hidden units 的数量,最后设成了 512,embedding 维度也设成了 512;
- 除了 CNN 以外,其他部分都用 SGD 来调参,随机初始化参数,固定学习率,无 momentum;
- 词典中只保留出现次数 > 5 的单词
Inference
在测试生成句子时使用了 beam search,beam size 设为 20。当把 beam size 设为 1(相当于 greedy search)时,BLEU 值降了 2 点左右。
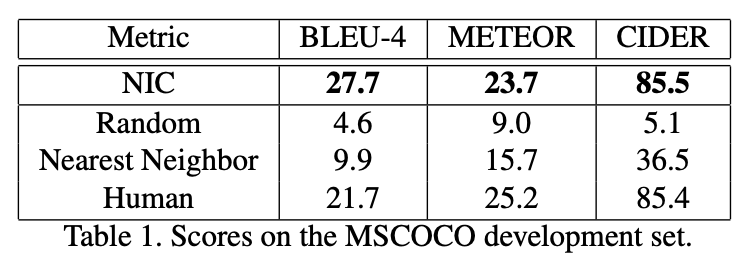
Experiments
Show, Attend and Tell
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. Kelvin Xu, et al. ICML 2015. [Paper] [Code]
由于原版代码是用(我不会的)Theano 写的,所以这里是俩用(我大概会的)PyTorch 写的复现代码:
首次把 Attention 机制用进 Image Captioning 中。
在上述 Encoder-Decoder 结构中,Encoder 和 Decoder 之间唯一的联系只有一个固定长度的语义向量 x−1,所以 Encoder 必须把原始输入的所有信息都压进 x−1 中。如果原始输入包含的信息较多, x−1 可能就无法表达所有信息。而且 x−1 携带的信息还可能被后面输入的信息覆盖掉。
于是就有了 Attention 机制,最先把它用在 seq2seq 结构中的论文是这篇做机器翻译的:
Neural Machine Translation by Jointly Learning to Align and Translate. Dzmitry Bahdanau, KyungHyun Cho, and Yoshua Bengio. arXiv 2014. [arXiv]
CNN
CNN 用了 VGGNet。
前面的论文是用全连接层输出的一个固定长度的向量当特征(高层特征),而这篇论文用了最后一个卷积层(用 Keras 的话说是 block5_conv3)的 H×W×D(14×14×512)的特征图来当特征(低层特征):
a={a1,...,aL},ai∈RD
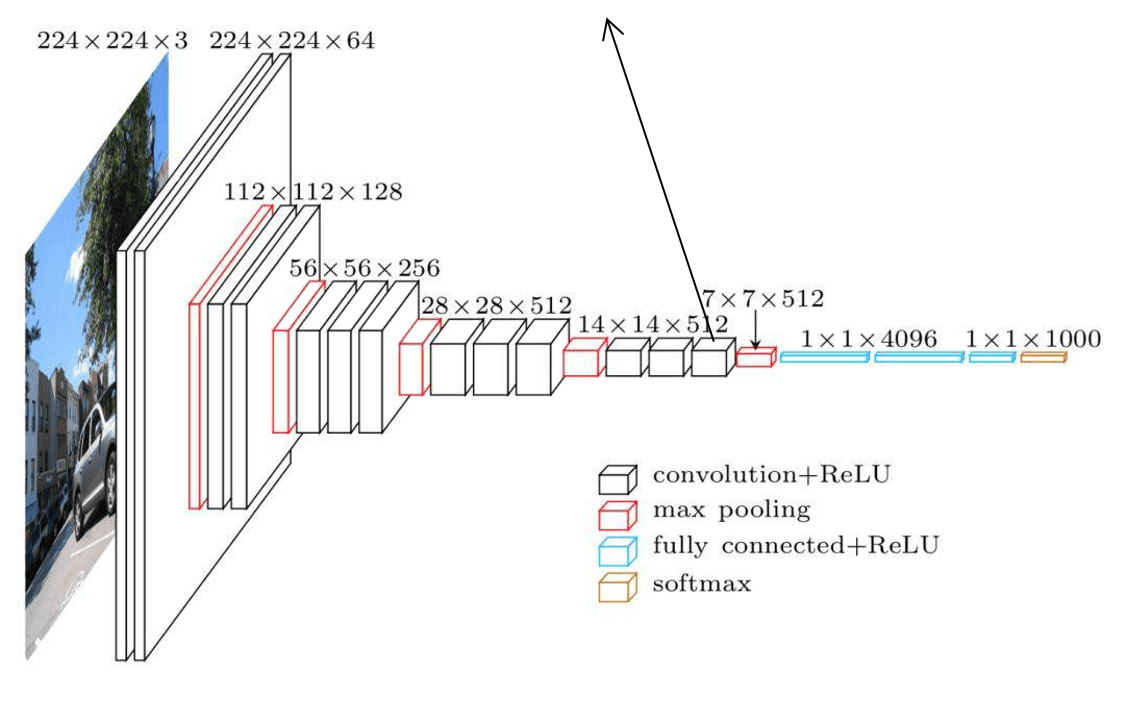 VGGNet 结构
VGGNet 结构
其中 H 和 W 为特征图的高度和宽度,D 为特征图的维度,L=H×W。相当于对于图片的 L 个位置各提一个特征,每个特征都是一个 D 维向量(annotation vector)。
于是接下来的 LSTM 就需要在这 L 个位置的特征里选有用的,这就是 Attention 机制。
LSTM + Attention
以下是论文里给的 LSTM 结构图和推导公式:
-
LSTM 结构:
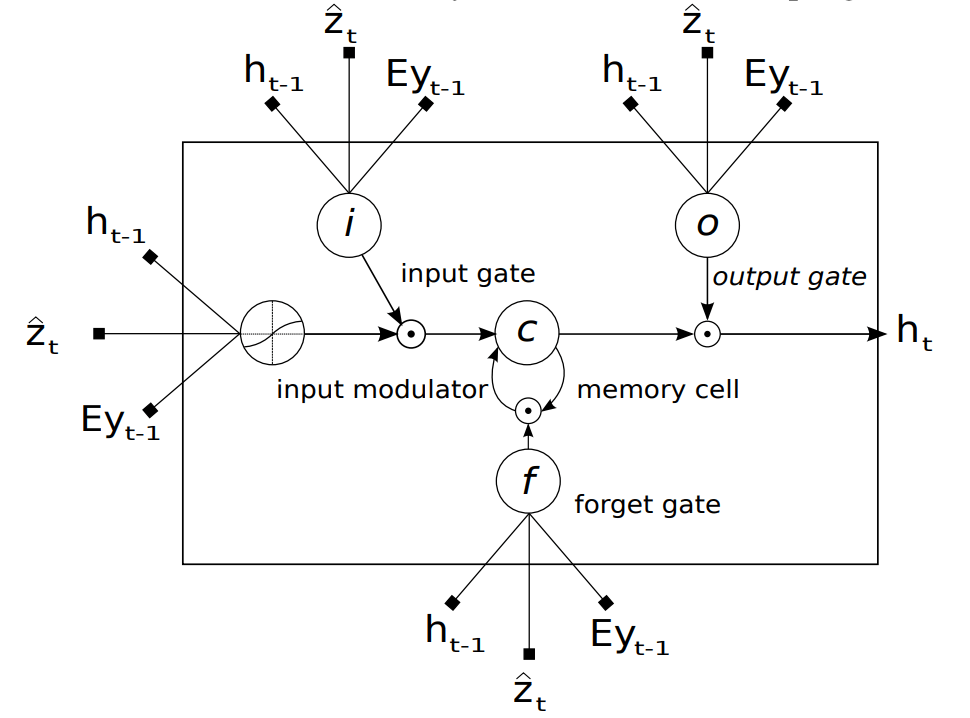
-
推导公式:
it=σ(WiEyt−1+Uiht−1+Ziz^t+bi)
ft=σ(WfEyt−1+Ufht−1+Zfz^t+bf)
ct=ftct−1+ittanh(WcEyt−1+Ucht−1+Zcz^t+bc)
ot=σ(WoEyt−1+Uoht−1+Zoz^t+bo)
ht=ottanh(ct)
但从代码实现来看(以原版代码为准),图应该画成这样(代码实现跟论文描述的出入会在后面提到)(图来自论文 Adaptive Attention):
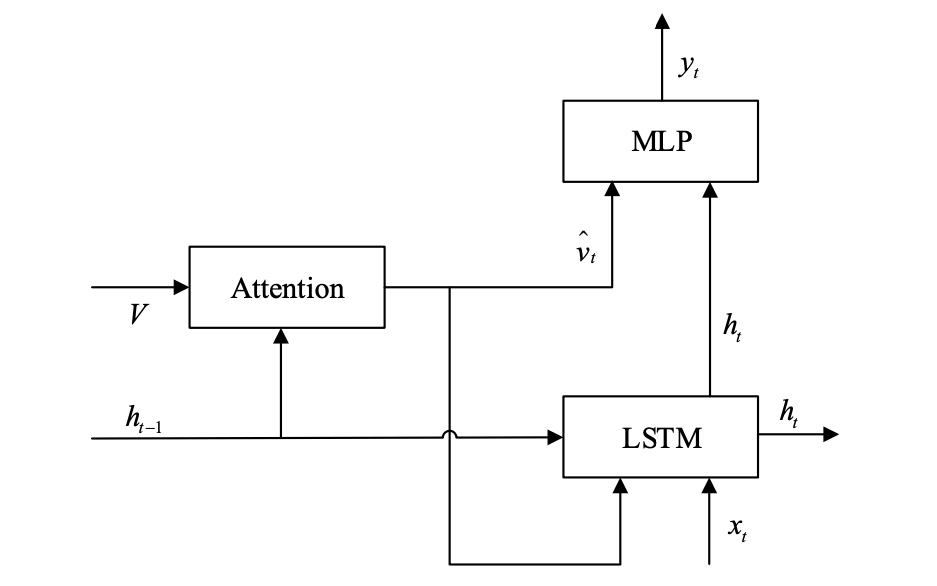
备注
虽然在图和推导式里,上一步输出 yt−1 也参与了这一步的计算,但代码(原版和复现)里似乎没有参与。
跟正常 LSTM 的区别是用 context vector z^t 来代替了当前输入 xt。
备注
按论文里的描述是这样,即 xt 完全没有参与计算。但代码(原版和复现)里是把 z^t 和 xt 拼到了一起作为输入。
z^t 由 ϕ 函数对 {a1,...,aL} 进行一些加权得到,αi 为 ai 的权重:
z^t=ϕ({ai},{αi})
Soft Attention 和 Hard Attention 的不同在于 ϕ 的不同。在 Soft Attention 中:
z^t=ϕ({ai},{αi})=βi∑Lαt,iai
β 是一个决定当前时间步要用多少 context 信息的门控信号:
β=σ(fβ(ht−1))
相当于在 Soft Attention 中,αt,i 代表图像的第 i 个位置的特征 ai 在 t 时刻输入 Decoder 的信息所占的比例,即对 ai 求加权平均。αt,i 由 Attention 模型 fatt(也就是一个 MLP)计算得到:
eti=fatt(ai,ht−1)
然后把 eti 归一化(softmax)后就得到了 αti:
αti=∑k=1Lexp(etk)exp(eti)
除了标准化自带的 ∑iLαti=1 这个限定以外,还对 αti 加了另一个限定,来避免图像某些部分的特征被忽略(论文里设的 τ=1):
t∑αti≈τ,τ≥DL
所以 Soft Attention 模型的训练目标是要最小化以下惩罚函数:
Ld=−log(p(y∣a))+λi∑L(1−t∑Cαti)2
细胞状态和隐状态初始值为(finit,c 和 finit,h 都是 MLP):
c0=finit,c(L1i∑Lai)
h0=finit,h(L1i∑Lai)
最终输出的单词概率分布为:
p(yt∣a,yt−1)∝exp(Lo(Eyt−1+Lhht+Lzz^t))
其中,Lo、Lh、Lz、E 都是需要学习的权重参数。
备注
似乎只有原版代码算是按照上面这个公式来算的单词概率(而且它依然没有考虑 yt−1),俩复现代码都直接把 ht 扔进 softmax 完事,即:yt=softmax(ht)。
Experiments
Adaptive Attention
Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning. Jiasen Lu, et al. CVPR 2017. [Paper] [Code]
不是每个单词的生成都需要利用图像特征,有的词的生成只需要依赖语义信息,如“the”、“of”等词,和跟在“talking on a cell”后面的“phone”等词。因此该论文的 Adaptive Attention 机制能决定当前时间步要用多少图像特征和多少语义信息。
CNN
用了 ResNet,最后一个卷积层输出 2048×7×7 的特征图,表示为:
A={a1,...,ak},ai∈R2048
对每个向量做以下变换:
vi=ReLU(Waai)
则最终的图像特征为:
V=[v1,...,vk]
论文还算了一个全局图像特征,即把特征图中所有向量做个算术平均,然后做个类似的变换:
ag=k1i=1∑kai
vg=ReLU(Wbag)
然后 LSTM 每个时间步的输入为把 word embedding 和 vg 拼到一起后的结果,即:
xt=[wt;vg]
Spatial Attention
首先对 Attention 机制做了一些修改:
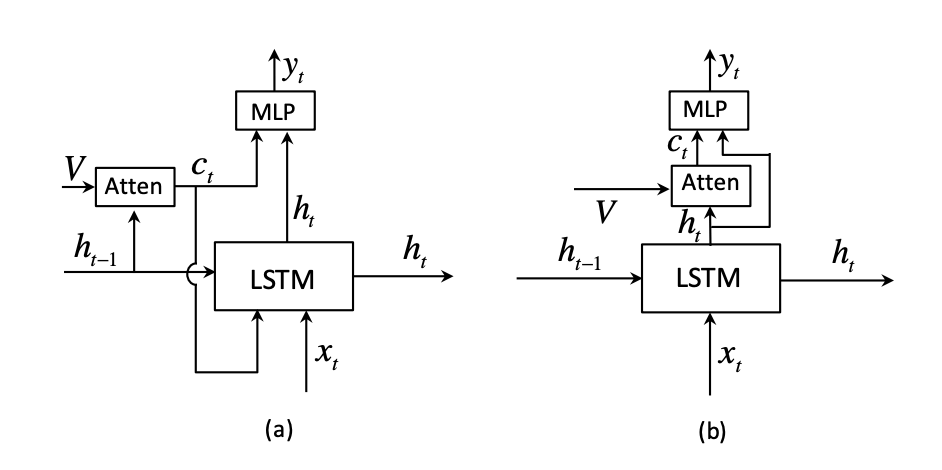 (a):Show, Attend and Tell 网络结构,(b):该论文的 Spatial Attention 网络结构
(a):Show, Attend and Tell 网络结构,(b):该论文的 Spatial Attention 网络结构
与上一篇论文的不同:
context vector ct 定义为:
ct=g(V,ht)
V=[v1,...,vk],vi∈Rd 是上一步中操作出来的图像特征,g 是 Attention 模型。
g 的具体实现如下,先算权重 αt(MLP + softmax):
zt=whTtanh(WvV+(Wght)1T)(1)
αt=softmax(zt)
1∈Rk 是一个元素全为 1 的向量,目的是跟 Wght 相乘得到 k×k 的矩阵。Wv,Wg∈Rk×d
和 wh∈Rk 都是要学习的权重参数。
然后对 V 加权平均,得到 ct:
ct=i=1∑kαtivti
Adaptive Attention
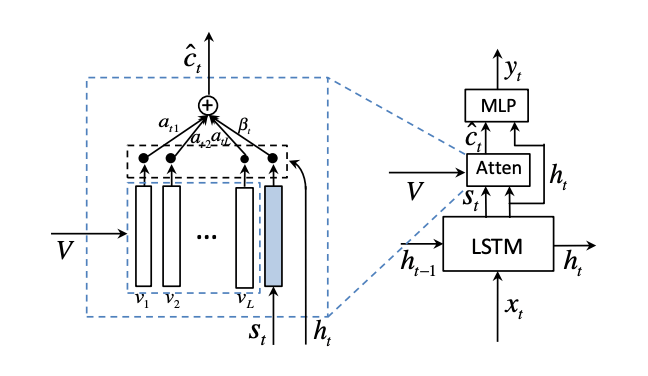
在 LSTM 上新增了一个叫 visual sentinel 的向量 st,用于记录一部分的细胞状态:
gt=σ(Wxxt+Whht−1)
st=gt⊙tanh(mt)
gt 是个门控信号,mt 是 t 时刻的细胞状态,σ 是 sigmoid 激活函数。跟 LSTM 输出门公式的形式是一样的,但是分别由不同的权重控制。
于是 Adaptive Attention 中的 context vector c^t 为:
c^t=βtst+(1−βt)ct
βt∈[0,1] 是一个控制 t 时刻要利用多少 st(语义信息)和 ct(图像特征)的门控信号(sentinel gate)。为了算出 βt,把 Attention 权重的计算公式也做了修改,新的权重 α^ 为:
α^t=softmax([zt;whTtanh(Wsst+(Wght))])
相当于把 zt 跟 whTtanh(Wsst+(Wght)) 拼了起来。这里的 Wg 跟公式 (1) 中的 Wg 是一样的,同时虽然论文中没说,但 whT 的确也是一样的。
α^t 有 k+1 个元素,则 βt 为:
βt=α^t[k+1]
单词概率分布为:
pt=softmax(Wp(c^t+ht))
Experiments
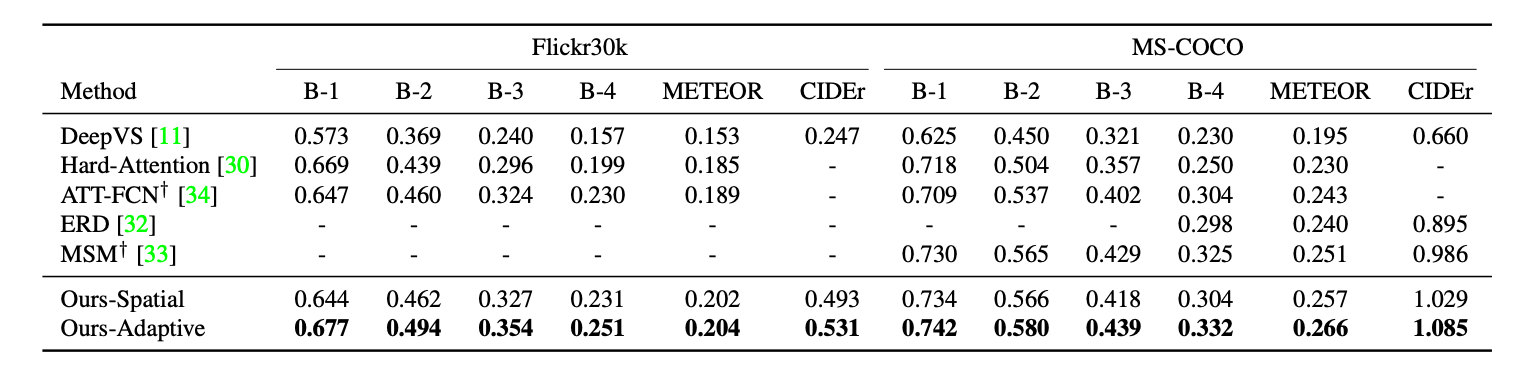
Self-critical
Self-critical Sequence Training for Image Captioning. Steven J. Rennie, et al. CVPR 2017. [Paper]
Pytorch 复现:ruotianluo/self-critical.pytorch
之前的方法都是用最大似然进行语言建模,在训练时最大化模型生成的单词序列的联合概率,从而最小化交叉熵损失。这种方法存在两个问题:
-
曝光偏差(exposure bias):训练时用了 teacher forcing,即解码器每个时刻的输入都是训练集中的真实单词(ground truth),而测试时,解码器每个时刻的输入是自己上一时刻生成的单词,如果某一个单词预测得不够准确,之后所有单词的预测都会受到影响;
-
训练目标和评价准则不匹配:训练时用的交叉熵损失函数,而验证时用的是 BLEU、ROUGE、METEOR、CIDEr 之类的指标,导致模型训练时无法做到充分的优化评估指标。
于是一个自然的想法是直接优化评估指标(CIDEr)。但由于生成单词的操作不可微,所以不能用一般的反向传播梯度下降来优化这些指标,因此考虑用强化学习(中的 Policy Gradient 方法)来优化。
Policy Gradient
如果把图像描述问题看成强化学习问题:
- agent:decoder
- environment:单词和图像特征
- policy:pθ,由模型参数 θ 决定
- action:对下一个单词的预测
- state:decoder 要更新的各种状态,如 LSTM 隐状态和细胞状态、 attention 权重等
- reward:r,CIDEr 值
训练目标是最大化期望 reward,因为要用梯度下降,所以写成最小化负期望 reward:
L(θ)=−Ews∼pθ[r(ws)]=−ws∑pθ(ws)r(ws)
其中,ws=(w1s,...,wTs) 是生成的句子,r(ws) 是 ws 上的 γ 折扣累积 reward:
r(ws)=r1+γr2+γ1r3+...+γT−1rT
对 L(θ) 求梯度:
∇θL(θ)=−∇θEws∼pθ[r(ws)]=−∇θws∑pθ(ws)r(ws)=−ws∑∇θpθ(ws)r(ws)=−ws∑pθ(ws)pθ(ws)∇θpθ(ws)r(ws)=−ws∑pθ(ws)∇θlogpθ(ws)r(ws)=−Ews∼pθ[r(ws)∇θlogpθ(ws)]
推导过程参考:Deep Reinforcement Learning: Pong from Pixels
实际训练时,会用蒙特卡洛的思想从 pθ 中按概率随机采样出一个单词序列 ws=(w1s,...,wTs) 来估计出梯度的近似值:
∇θL(θ)≈−r(ws)∇θlogpθ(ws)
因为采样的每一步都具有较大的随机性,可能会使最终得到的样本之间差异巨大,所以一般认为这种基于蒙特卡洛采样的近似方法会导致估计出的梯度有较高的方差。于是为了引入了一个 baseline b 来减小方差,即:
∇θL(θ)=−Ews∼pθ[(r(ws)−b)∇θlogpθ(ws)]
只要 b 不依赖于 ws,减去一个 b 并不会改变梯度的值,证明过程为:
Ews∼pθ[b∇θlogpθ(ws)]=bws∑∇θpθ(ws)=b∇θws∑pθ(ws)=b∇θ1=0
所以估计出的梯度为:
∇θL(θ)≈−(r(ws)−b)∇θlogpθ(ws)
由链式法则可以得到:
∇θL(θ)=t=1∑T∂st∂L(θ)∂θ∂st
其中 st 是 softmax 的输入,是一个长度为词典大小的向量,表示了 t 时刻词典中每个单词的分数。
把 ∂st∂L(θ) 近似一下可以得到:
∂st∂L(θ)≈(r(ws)−b)(pθ(wt∣ht)−1wts)(2)
其中 1wts 是单词 wts 的独热编码向量。这个近似相当于把 wts 当成了 t 时刻 pθ(wt∣ht) 的目标输出,在 MIXER 的论文里有解释。
因为公式 (2) 的第二项 (pθ(wt∣ht)−1wts) 一定小于 0,所以当样本的 reward 大于 baseline b 时,梯度为负,梯度下降时就会提高单词 wts 的分数,否则就会抑制 wts 的分数。一般来说会用对当前模型的 reward 的平均值的估计函数作为 baseline,如在 MIXER 中,baseline rˉt 是一个线性回归模型,通过优化均方误差 ∥rˉt−r∥2 得到。
SCST
self-critical sequence training
论文把 baseline 定义为当前模型通过 greedy decoding 得到的句子 w^ 的 reward。所以叫 self-critical,因为 baseline 也是自己生成的,相当于自己跟自己比。于是有:
∂st∂L(θ)≈(r(ws)−r(w^))(pθ(wt∣ht)−1wts)
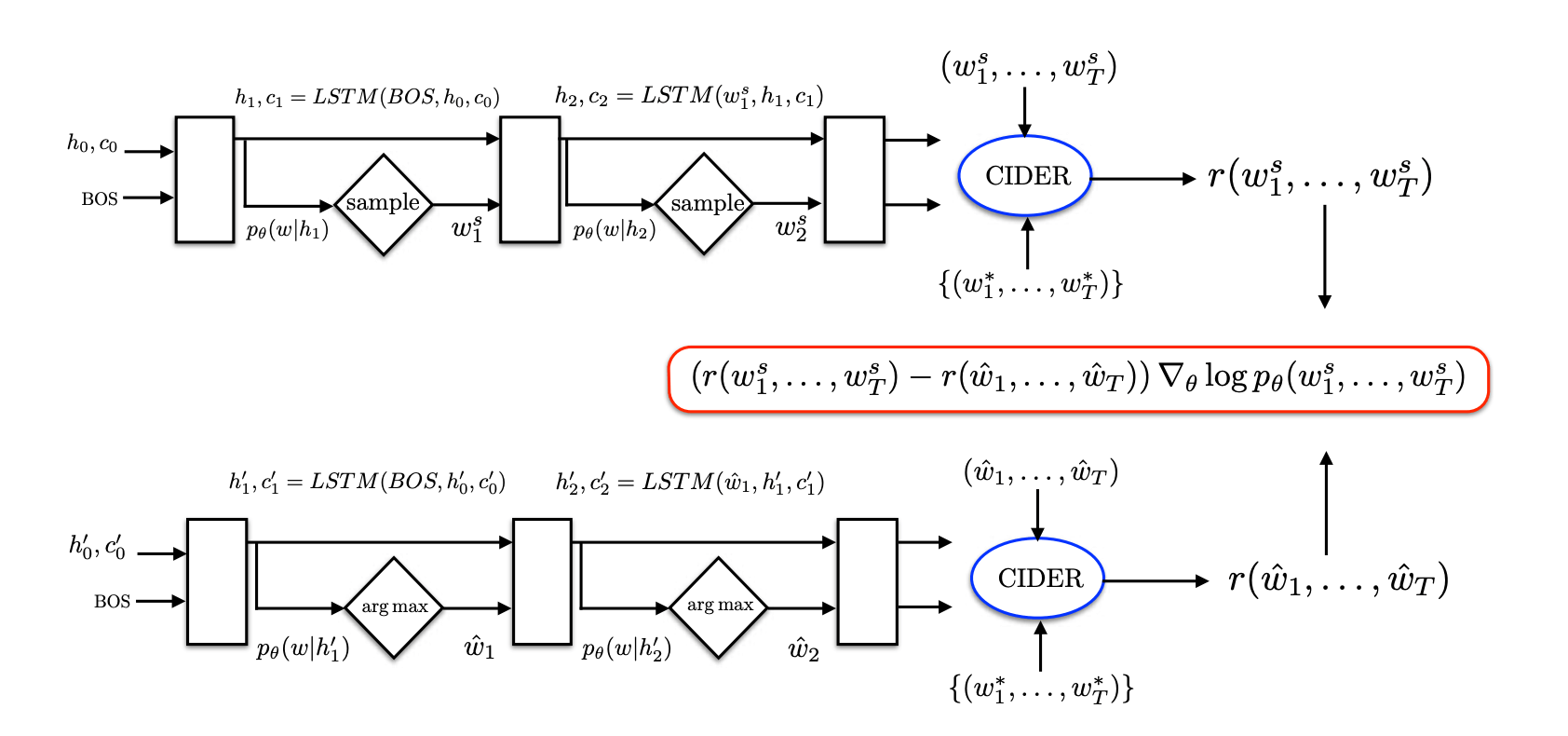
论文认为这样做的优点是:
- 不用另外训练一个模型来当 baseline,只需要用现有模型 inference 一遍,降低了训练复杂度
- 训练和测试阶段的一致性,都用的同样的生成方法(但训练时不是随机采样吗…)
- 梯度方差低于 MIXER,训练得更快(用 SGD 时)
用强化学习的方法训练之前,会先用交叉熵损失进行预训练。
Experiments
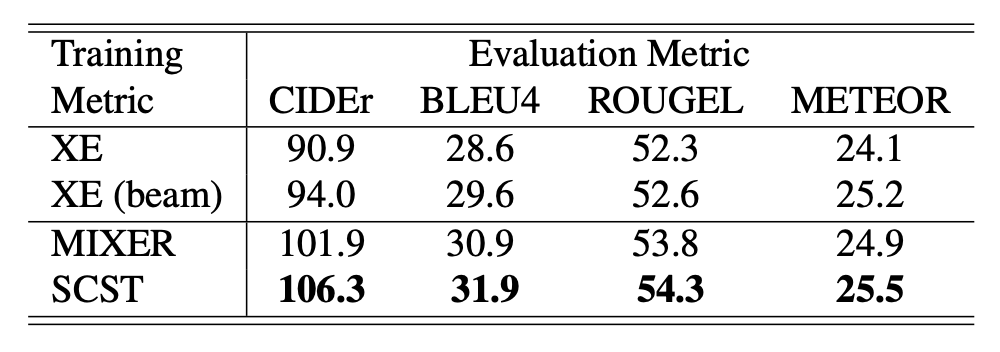
-
与以优化交叉熵损失(XE)为目标的模型和用 MIXER 方法训练的模型的对比实验:
-
尝试 curriculum learning,即先对最后一个单词以优化 CIDEr 为目标进行训练,前面的词则以优化交叉熵损失为目标进行训练,然后每个 epoch 增加一个用 CIDEr 进行训练的单词。但这种方法至少在 MSCOCO 上对效果没有提升。
-
尝试以优化别的指标为目标,但优化 CIDEr 的效果是最好的,能把所有指标都往上拉:
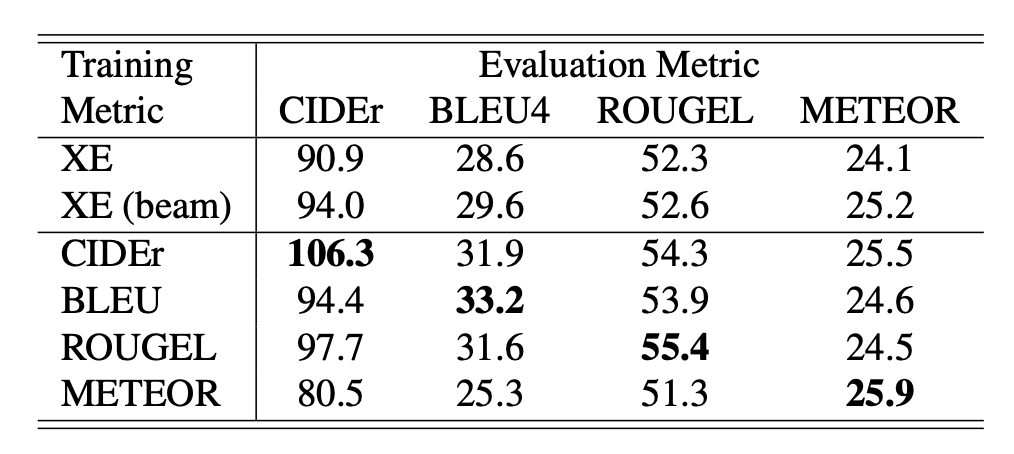
-
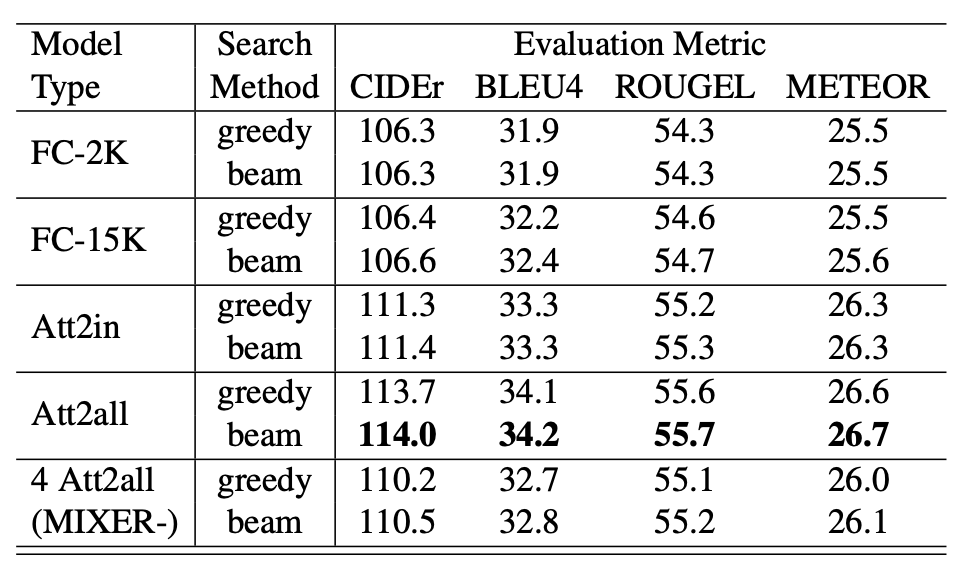
发现 beam search 对 RL 训练出来的模型效果提升很小:
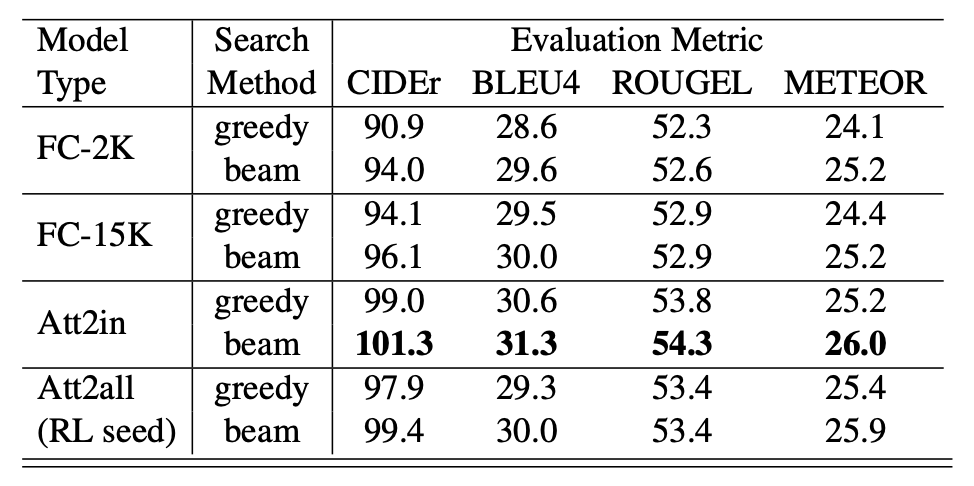
作为对比,这是 beam search 对用交叉熵损失训练出来的模型效果提升:
-
似乎能对 objects out-of-context (OOOC) 的图片生成比较好的结果
Image Aesthetic Captioning
Aesthetic Critiques
Aesthetic Critiques Generation for Photos. Kuang-Yu Chang, Kung-Hung Lu, and Chu-Song Chen. ICCV 2017. [IEEE] [Paper] [Code] [Dataset]
开图像美感描述这个坑的第一篇论文,数据集 PCCD 的提出者(虽然我并没有找到这个数据集)。该论文考虑从不同美学角度来对图片进行美感描述,对每个角度而言大概就跟 Image Captioning 差不多了。
训练数据结构:
D=(Φi,Ci,ai),i∈{1...N}
Φi 是第 i 张图片,Ci 是它的描述(同一张图片可能有多个不同角度的描述),ai(i∈{1...L})是该描述的角度。在此之外,还有一个 pi,l∈[0,1] 来描述图片 Φi 在角度 l 上的美感分数。
Aspect-oriented
Baseline - Aspect-oriented (AO) Approach
AO 中,训练数据中每张图都只带有一个角度的描述,即 (Φi,Ci,l)。然后用 CNN-LSTM 在每个角度的数据上进行训练。
相当于要对 L 个角度各建一个 CNN-LSTM 模型。关于 CNN-LSTM 可以参考 Show and Tell 那篇论文。
CNN 还会用 {(Φi;pi,l)} 进行训练。在测试时,它会输出图片在每个角度上的美感分数,然后把得分最高的角度 l∗ 所对应的 CNN-LSTM 模型的输出结果当做最终结果。流程图如下:
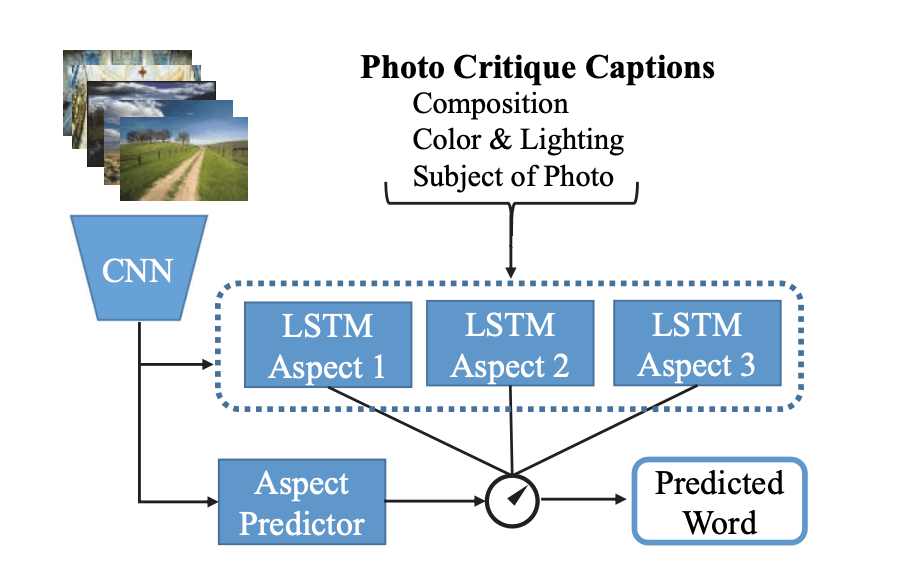
Aspect-fusion
AO 只能输出一个角度的描述,比较单一。为了解决这个问题,论文先尝试把整个数据集都扔进 CNN-LSTM 训练,但效果不好。
Aspect-fusion (AF) Approach
于是论文决定在测试时把 AO 中每个角度的 CNN-LSTM 模型输出的隐状态 hl={hl,t∣t=1...T,l=1...L} 用 Soft Attention 融合一下之后,当做输入扔进一个新的 LSTM 中,于是新的 LSTM 的递推公式为:
(gτ,yτ)=F(gτ−1,xτ,sτ)
yτ 为概率分布,xτ 为当前输入,gτ−1 为上一时刻的隐状态,sτ 为 Soft Attention 融合出来的 context vector。
Soft Attention
sτ 相当于是对 hlt 求加权平均:
sτ=l=1∑Lt=1∑Tαltτ(h,gτ−1)hlt
其中,权重 αltτ 需要在 Soft Attention 模型中生成:
eltτ=A(gτ−1,hlt)=Wγ(Ugτ−1+Vhlt)
αltτ=∑p=1L∑q=1Texp(epqτ)exp(eltτ)
其中,γ 是 ReLU 激活函数,W∈Rn×n、U∈Rn×n 和 V∈Rn×n 是需要学习的权重,n 是 LSTM 隐藏层大小(论文里面设的 768)。
流程图如下(自行加了一些不知对不对的标注):
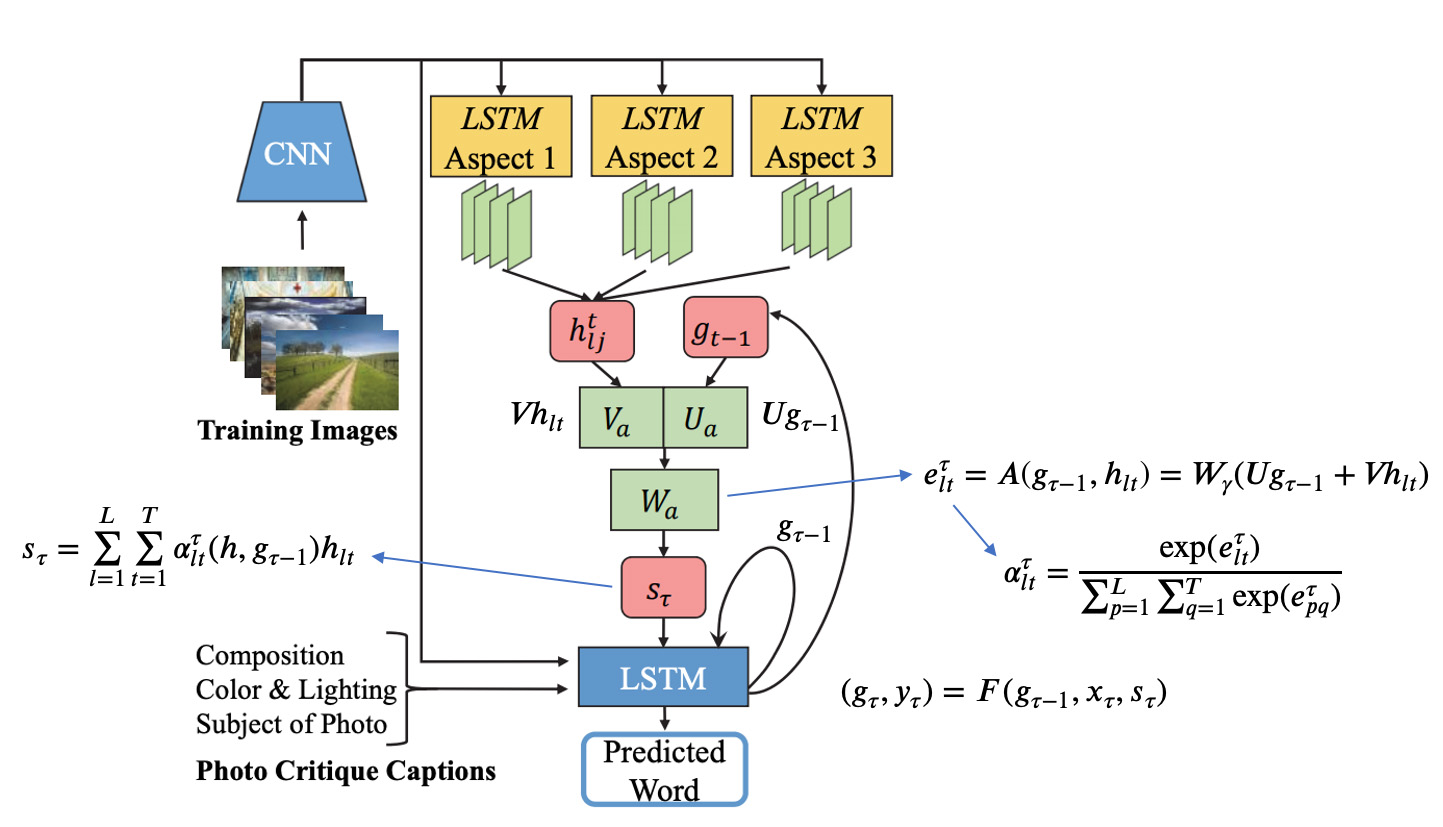
相当于论文认为 CNN-LSTM 输出的隐状态可以被看做每个角度的输入的深层特征,然后 Soft Attention 机制又可以很好的把它们融合到一起。
困惑:按照代码里面的写法,第二个 LSTM 明明已经是在生成融合各个角度之后的句子了,却依然把每个角度的句子分别输入和用来算损失,感觉说不通,虽然的确也没有角度融合后的 ground truth 就是了…
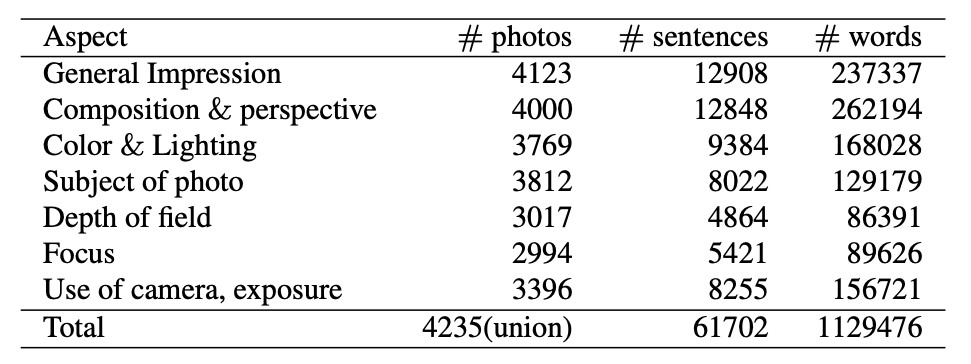
PCCD
图片和评论来源于 GuruShots,评论被分为了 7 个角度,每个角度都有评分(评分范围为 1-10):
Experiments
因为不是每个角度都有评论,所以实验时论文只选了 3 个角度(composition and perspective、color and lighting、subject of photo)。为了控制词典大小,词典中只保留出现次数 > 5 的单词,其他单词会被映射为 UNK。
论文直接用了 NeuralTalk2 来当 CNN-LSTM 模型,拿了在 MSCOCO 数据集上预训练好的模型在 PCCD 上 fine-tune(只 fine-tune 了 LSTM 部分,CNN 部分保持不变)。
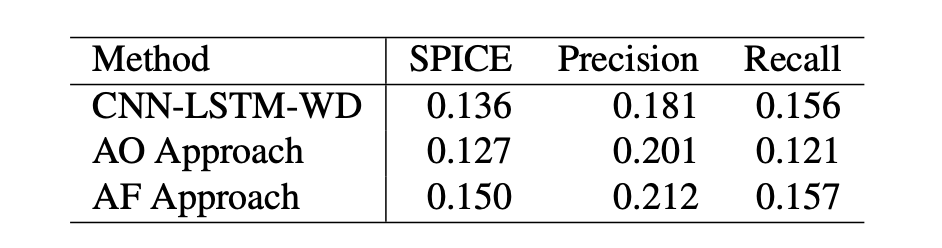
评估指标用了 SPICE。
实验结果: