基于正则(regularization-based)的持续学习:用一个表示参数重要程度的正则项来控制参数在未来的任务中的更新幅度。
持续学习
传统的机器学习要求训练样本之间是 i.i.d(Independent and Identically Distributed,独立同分布)的,为了达到这个目的往往会随机打乱训练数据。但如果要让模型处理分布在变化的连续数据,如果不做任何处理依然按传统方法来训练,就会出现灾难性遗忘(Catastrophic Forgetting),因为新的数据会对模型造成干扰(interference)。模型会调整它学到的关于旧数据的参数以适应新任务,这样在旧数据上学到的知识就会被遗忘。
Continual / Lifelong / Incremental / Cumulative Learning(持续学习 / 终身学习 / 增量学习)就是为了解决这个问题(我从未见过命名如此不统一的方向 2333)。标准版持续学习的目标是(叫它标准版是因为最近的很多研究给持续学习加了一些新目标):
为了搞定灾难性遗忘,常见的三种套路是:
-
Dynamic Expansion:既然问题在于关于旧任务的参数会被干扰,那就不用这些参数来学习新任务了,直接搞一批新的参数来学新任务。这样模型的参数就会越来越多,所以叫 dynamic expansion。模型参数太多了之后可能会很难训练。为了让参数不要增加得太快,有些方法会加一些模型剪枝知识蒸馏一类的压缩操作进来。
-
Rehearsal:如果让新任务上的梯度尽可能接近旧任务上的梯度,那在旧任务上学习到的知识就不会被遗忘多少。这种思路需要去搞一些旧数据,而搞旧数据的方法又大概能分为两种:
-
Extra Memory:直接存一些旧数据,这样就需要额外的存储空间;
-
Generative Replay:用旧数据训练一个生成模型(如 GAN、VAE 等),然后用这个生成模型来生成旧数据。这样不需要额外的存储空间,但模型参数会变多(多了生成模型的参数)。
不过我很好奇用生成模型模拟旧数据的效果,和把生成模型的权重占的存储空间全拿去存旧数据的效果哪个更好。假设权重几十或几百兆,如果直接把它拿来存旧数据,假设一张图片几百 K(因为大多数持续学习论文的实验设置都是在做图像分类,所以这里考虑存图片),也能存几百张了。考虑到目前生成模型生成的图片质量都没有很高,在存储空间一样大的前提下它的效果能不能超过直接存几百张旧图片的效果我觉得是不一定的。我还是很希望看到有论文做这种对比实验的,不过目前似乎还没看到这样做的?虽然我也没看过多少论文就是了…
-
Regularization:直觉上来说更优雅的一类方法,毕竟不用额外存储空间也不用增加模型参数。这种方法会加一些正则项来避免跟旧任务关联较大的参数更新幅度过大。这种方法存在的基础是现在的绝大多数神经网络都是过参数化(over-parameterization)的。本文要理的一些方法就属于这一类。
直觉上的理解
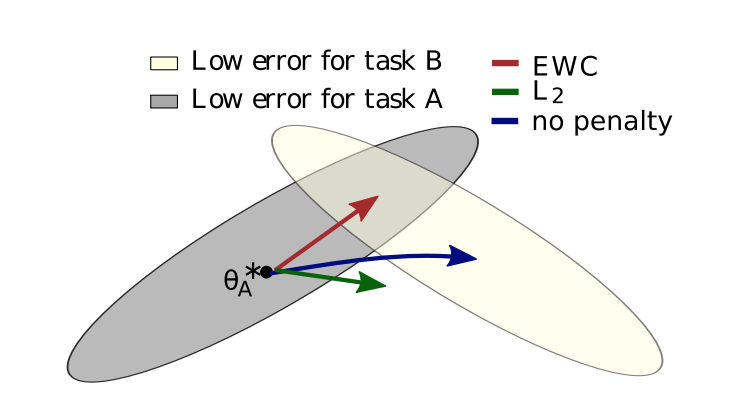 图片来源:论文 Overcoming Catastrophic Forgetting in Neural Networks
图片来源:论文 Overcoming Catastrophic Forgetting in Neural Networks
上图是参数在参数空间里的变化轨迹。蓝色的箭头相当于在任务 A(可以推广为旧任务)上训练完之后,直接拿去任务 B(可以推广为新任务)上 fine-tune。这样在学完任务 B 之后,基本就把任务 A 忘得差不多了。
那么一个想法是加一个正则项(L2),让在任务 B 上训练完后的参数不能离在任务 A 上训练完后的参数太远,即绿色箭头。但直接加 L2 正则项没有考虑不同参数对任务的重要性,对任务 A 特别重要的参数限制应该大一些,而不那么重要的参数则不用怎么限制,不然任务 B 就学不好了。
于是红色箭头就是很多 regularization-based 的方法的思想:计算一下每个参数 θi 对任务 A 的重要性 Ωi,然后加了正则项的损失函数变成(θA,i* 是在任务 A 上训练完后得到的最优参数):
L(θ)=LB(θ)+2λi∑Ωi(θi−θA,i*)2
只不过这些方法计算重要性 Ωi 的方式有所不同。
EWC
Overcoming Catastrophic Forgetting in Neural Networks. James Kirkpatrick, et al. PNAS 2017. [Paper]
EWC(Elastic Weight Consolidation)
参数重要性
如果直接上结论的话,参数 θi 的重要性 = Fisher 信息矩阵的第 i 个对角线元素,也即:
Ωi=∣DA∣1x∈DA∑∂θi∂logpθ(Y=yx*∣x)θ=θA*2
其中 yx* 是模型 pθA*(y∣x) 对 x 的输出。
贝叶斯视角
如果按照贝叶斯方法来学习参数的话,灾难性遗忘并不会发生。贝叶斯方法希望估计出参数的后验分布:
p(θ∣D)=p(D)p(θ,D)=p(DA,DB)p(θ,DA,DB)=p(DB∣DA)p(DA)p(θ,DB∣DA)p(DA)=p(DB∣DA)p(θ,DB∣DA)=p(DB∣DA)p(DB∣θ,DA)p(θ∣DA)=p(DB)p(DB∣θ)p(θ∣DA)
最后一步是因为 DA,DB 相互独立。这个形式实际上就是增量贝叶斯公式(incremental version of Bayes’ rule)。
那么有:
logp(θ∣D)=logp(DB∣θ)+logp(θ∣DA)−logp(DB)
对于右边的这三项,第一项 logp(DB∣θ) 很明显就是 DB 上的损失函数取负 −LB(θ),第三项 logp(DB) 是个参数无关的常数,于是优化目标就变为了(实际上就是最大后验估计(MAP)):
θ=argθmaxlogp(θ∣D)=argθmax(−LB(θ)+logp(θ∣DA))=argθminLB(θ)−logp(θ∣DA)
可以看到这个优化目标相当于一边最小化 DB 上的损失,一边最大化 DA 上的参数后验 p(θ∣DA),从而避免了灾难性遗忘的发生。
那么我们需要求的就是 p(θ∣DA),但这个后验是 intractabe 的,我记得我在好几个地方都写过它为啥 intractabe 所以这里就不写了…那么我们又需要把它近似出来,常用的近似方法大概就是变分推断、MCMC、拉普拉斯(Laplace)近似之类的,论文用了拉普拉斯近似。
btw,可以看到相比 MLE,上式就是多了一项 −logp(θ∣DA)。所以也可以理解为,论文就是在把这一项设计成结构化风险里的正则项。
拉普拉斯近似
拉普拉斯近似的目标是用一个高斯分布来近似 p(θ∣DA)。假设它是个高斯分布:
p(θ∣DA)=N(σ,μ)=2πσ1e−2σ2(θ−μ)2
⇒logp(θ∣DA)=log2πσ1−2σ2(θ−μ)2
右边其实是在取 ln,不过这里 log 和 ln 没有本质区别。
令 f(θ)=logp(θ∣DA),当 θ=θA* 时取最优解,那么在 θ=θA* 处对 f(θ) 泰勒展开:
f(θ)=f(θA*)+雅克比矩阵(∂θ∂f(θ)θ=θA*)(θ−θA*)+21(θ−θA*)⊤海森矩阵(∂2θ∂2f(θ)θ=θA*)(θ−θA*)+o(θA*)
因为 θA* 使得 f(θ) 有极大值(这里似乎证明了一定有这个极大值),所以 f(θ) 在 θ=θA* 处的一阶导为 0,二阶导为负(海森矩阵负定),并且我们忽略掉三阶及以上的项,那么 f(θ) 可以近似为:
f(θ)=log2πσ1−2σ2(θ−μ)2≈f(θA*)+21(θ−θA*)2f′′(θA*)
为了方便这里就不强调矩阵了,记住 f′′(θA*) 是个海森矩阵就好 2333。因为 log2πσ1 和 f(θA*) 都是参数无关的常数,所以:
−2σ2(θ−μ)2=2(θ−θA*)2f′′(θA*)
所以:
μ=θA*
σ=−f′′(θA*)1
高斯分布的两个超参求出来了,p(θ∣DA) 也就求出来了,现在优化目标可以写成:
θ=argθminLB(θ)−logp(θ∣DA)=argθminLB(θ)−21(θ−θA*)2f′′(θA*)
f(θA*) 是个常数所以可以省掉。相当于最大化 p(θ∣DA) 变成了最大化 21(θ−θA*)2f′′(θA*)。
那么现在问题又变成了怎么求 f′′(θA*)。f′′(θA*) 能直接算出来,但是这里参数 θ 是 n 维向量,所以 f′′(θA*) 是 n×n 的海森矩阵,计算的时间和空间复杂度都比较大。为了减小计算开销,论文把海森矩阵转成了 Fisher 信息矩阵。
Fisher 信息矩阵
首先,一个结论是 Fisher 信息矩阵等于海森矩阵的期望取负(这里是证明过程):
Fij=−E[f′′(θA*)]=−Ep(θ∣DA)∂θiθj∂2logp(θ∣DA)θ=θA*
为了省计算量,只取了 Fisher 信息矩阵的对角线,相当于假设各参数之间相互独立:
Fii=−Ep(θ∣DA)∂2θi∂2logp(θ∣DA)θ=θA*
之所以要转成 Fisher 信息矩阵,是因为 Fisher 信息矩阵可以只靠求一阶导算出来(基本定义),一阶导的计算复杂度比二阶导要低很多:
Fii=−Ep(θ∣DA)∂θi∂logp(θ∣DA)θ=θA*2
最大化 logp(θ∣DA) 跟最大化 logp(y∣x) 是一个意思,而求期望可以用蒙特卡洛采样来近似,所以:
Fii≈−Ex∼DA,y∼pθ(y∣x)∂θi∂logp(y∣x)θ=θA*2
其中 x 是从任务 A 的样本里采样出来的,y 是模型 pθA*(y∣x) 对 x 的输出。这是需要注意的一点,y 是从模型里采样出来的,不是直接从数据分布里采样的。所以求 Fisher 信息矩阵时至少需要再额外来一次反向传播流程,因为需要把 pθA*(y∣x) 的输出拿来当 ground truth,然后重新算一遍损失,然后再求一次梯度。
当然的确也有直接从数据分布里采样 y 的做法,叫 empirical Fisher,这样倒是可以把现成算好的梯度直接拿来用。
论文在算期望时把每个样本都采样了一遍,所以相当于是对每个样本上的梯度的平方求平均:
Fii=∣DA∣1x∈DA∑∂θi∂logpθ(Y=yx*∣x)θ=θA*2
其中 yx* 是模型 pθA*(y∣x) 对 x 的输出。
于是最终的损失函数为:
L(θ)=LB(θ)−2λf′′(θA*)(θ−θA*)2=LB(θ)+2λi∑Fi(θi−θA,i*)2
因为 Fisher 信息矩阵是海森矩阵的期望取负,所以这里从减号变成了加号。
我认为的另一个理解方式是,Fisher 信息矩阵也反映了我们对参数估计的不确定度。二阶导越大,说明我们对该参数的估计越确定,同时 Fisher 信息也越大,正则项就越大。于是越确定的参数在后面的任务里更新幅度就越小。
更多关于 Fisher 信息矩阵的细节可以参考我的这篇博客。
多个任务
考虑一下有三个任务 DA,DB,DC 的情况,这时的参数后验为:
log(θ∣DA,DB,DC)=logp(DC∣θ)+log(θ∣DA,DB)+constant
其中 log(θ∣DA,DB) 已经被近似出来了:
log(θ∣DA,DB)≈logp(DB∣θ)+21i∑λAFA,i(θi−θA,i*)2+constant
而最大化 logp(DB∣θ) 跟最大化 logp(θ∣DB) 是一个意思,logp(θ∣DB) 又可以近似为:
logp(θ∣DB)≈21i∑λBFB,i(θi−θB,i*)2
那么 log(θ∣DA,DB,DC) 可以近似为:
log(θ∣DA,DB,DC)≈logp(DC∣θ)+21i∑(λAFA,i(θi−θA,i*)2+λBFB,i(θi−θB,i*)2)+constant
相当于 EWC 会针对 θA,i* 和 θB,i* 各加一个惩罚项,来保证 θC,i* 跟 θA,i* 和 θB,i* 都尽量接近。如果任务推广到多个,那么 EWC 会为每个历史任务上训练完后的最优参数 θ1*,θ2*,…,θT−1* 都维护一个惩罚项,即:
LTregularization=21i∑(t<T∑λtFt,i(θi−θt,i*)2)
所以惩罚项数量会随任务数量线性增长,造成较大的计算开销。而 Online EWC 给出了一个不管有多少任务都只用维护一个惩罚项的解决方案。
其他
-
不同任务上的参数差异较大时,再把泰勒展开的高阶项近似为 0 就很勉强了
-
只取 Fisher 信息矩阵的对角线,相当于假设各参数之间相互独立,但实际上参数之间肯定有关联
-
原论文写得相当简洁,给人一种好像很快就能看明白的错觉,实际上背地里公式推导省略了一大堆 orz
Online EWC
On Quadratic Penalties in Elastic Weight Consolidation. Ferenc Huszár, et al. arXiv 2017. [Paper]
EWC 会为每个历史任务上都维护一个惩罚项,所以惩罚项数量会随任务数量线性增长,造成较大的计算开销。但从直觉上来说,θB* 本来就是在对 θA* 加了惩罚项的情况下估计出来的,那么在估计 θC* 的时候就只需要对 θB* 加惩罚项就够了,就没必要再维护 θA* 的惩罚项了。推广到多个任务,即在估计 θT* 的时候只需要维护一个 θT−1* 的惩罚项就好。
在上一节中我们已经得到 log(θ∣DA,DB,DC) 的近似:
log(θ∣DA,DB,DC)≈logp(DC∣θ)+21i∑(λAFA,i(θi−θA,i*)2+λBFB,i(θi−θB,i*)2)+constant
现在我们认为 θB,i* 和 θA,i* 是差不多的(毕竟这就是 regularization-based 方法的目标),所以 (θi−θB,i*) 和 (θi−θA,i*) 也是差不多的。那么 log(θ∣DA,DB,DC) 可以进一步近似为:
log(θ∣DA,DB,DC)≈logp(DC∣θ)+21i∑(λAFA,i+λBFB,i)(θi−θB,i*)2+constant
推广到 T 个任务,优化目标即为:
θT∗=argθmin{−logp(DT∣θ)−21i∑(t<T∑λtFt,i)(θi−θT−1,i*)2}
所以可以看到,我们并不需要为每个历史任务都维护一个惩罚项,我们只需要对上一个任务训练完后的最优参数加惩罚项就好。
Progress & Compress: A Scalable Framework for Continual Learning. Jonathan Schwarz, et al. arXiv 2018. [Paper]
这就是 Online EWC 的思想,其正则项为:
LTregularization=21i∑F^T−1,i(θi−θT−1,i*)2
其中 F^ 是 Fisher 信息矩阵 F 的(带权)累加和:
F^t=γF^t−1+Ft
F^1=F1
γ<1 是一个超参数,相当于之前的任务上的算出来的参数重要性对最终结果的贡献会逐渐降低。
P.S. 讲道理我也不知道它为啥要取 online EWC 这个名字,我第一眼看到这个名字还以为它要往 online learning 上靠,结果并没有…
MAS
Memory Aware Synapses: Learning What (Not) to Forget. Rahaf Aljundi, et al. ECCV 2018. [Paper] [Code]
MAS(Memory Aware Synapses)
参数重要性
对于第 k 个输入数据点 xk,如果对第 i 个参数 θi 做了一个很小的改变 δ,就让模型 F 的输出结果有了很大的变化,就说明 θi 是很重要的。
模型输出对所有参数 θ={θi} 的变化的变化量可以近似为:
F(xk;θ+δ)−F(xk;θ)≈i∑gi(xk)δi
⇒gi(xk)≈∂θi∂F(xk)
gi(xk) 可以被看做参数 θi 的变化对模型对样本 xk 的输出的影响。可以看到 gi(xk) 就是模型函数对参数 θi 的偏导。
重要性 Ωi 为所有样本上的偏导的均值:
Ωi=N1k=1∑N∥gi(xk)∥
每个任务训练完后,都会算一个刚训练完的任务中每个参数的重要性,然后累加到之前的 Ωi 上。一直累加可能会让 Ωi 变得很大,造成梯度爆炸,于是该论文一作后来的一篇工作 Task-Free Continual Learning 中用的是迄今为止所有 Ωi 的平均值。
L2 范数
大多数神经网络的输出 F(xk;θ) 都是一个 n 维向量,比如分类任务会输出每个类别上的概率。这样在求每个 gi(xk) 的时候,算的都是向量的偏导,需要做 n 次反向传播。
为了降低计算复杂度,论文给了另一个可选的方法:对 F(xk;θ) 的 L2 范数(的平方)求偏导,这样算的就是标量的偏导了,只需要一次反向传播:
gi(xk)=∂θi∂[ℓ22(F(xk))]
IS
Continual Learning Through Synaptic Intelligence. Friedemann Zenke, et al. ICML 2017. [Paper] [Code]
IS(Intelligent Synapses)
MAS 算的是参数改变对模型输出的影响,而 IS 算的是参数改变对损失函数的影响:
L(θ(t)+δ(t))−L(θ(t))≈i∑gi(t)δi(t)
⇒gi(t)≈∂θi∂L
其中 θ(t) 为任务 t 训练完后的参数。如果算一个任务 μ−1 到任务 μ 的更新轨迹上所有微小变化的总和,即对更新开始时刻 tμ−1 到结束时刻 tμ 积分:
∫tμ−1tμg(t)δ(t)dt=i∑∫tμ−1tμgi(t)δi(t)dt=−i∑ωiμ
⇒ωiμ=−∫tμ−1tμgi(t)δi(t)dt
ωiμ 就是参数 θi 的变化对损失函数输出的影响。在 offline 场景下,ωiμ 直接就能通过损失函数输出值的变化量算出来。与 EWC 和 MAS 不同的是,IS 还可以在 online 场景下计算 ωiμ,这时 gi(t) 可以用 gi(t)=∂θi∂L 来近似,而 δi(t) 就相当于 δi(t)=θi′(t)=∂t∂θi。
最后,参数重要性的计算公式为:
Ωiμ=ν<μ∑(Δiν)2+ξωνμ
其中 Δiν=θi(tν)−θi(tν−1) 是为了保证 Ωiμ 的尺度跟损失函数输出值的尺度是差不多的。为了避免分母为 0 所以加了一个 ξ。
附录
海森矩阵
令 x=(x1,x2,…,xn),多元函数 f(x) 在 x=x0 处的的二阶偏导是一个海森矩阵(Hessian matrix):
f′′(x0)=H=∂x1x1∂f∂x2x1∂f⋮∂xnx1∂f∂x1x2∂f∂x2x2∂f⋮∂xnx2∂f……⋱…∂x1xn∂f∂x2xn∂f⋮∂xnxn∂fx=x0
泰勒展开
f(x) 在 x=x0 处的泰勒展开公式为:
f(x)=0!f(x0)+1!f′(x0)⋅(x−x0)+2!f′′(x0)⋅(x−x0)2+o(x0)
o(x0) 为高阶项。在 f(x) 是多元函数的情况下,一阶导要写成雅克比矩阵(Jacobian matrix),二阶导要写成海森矩阵:
f(x)=0!f(x0)+1!Jf(x0)⋅(x−x0)+(x−x0)⊤⋅2!Hf(x0)⋅(x−x0)+o(x0)
L2 范数
向量 x=[x1,x2,…,xn] 的 L2 范数(L2 norm)为:
∥x∥2=(i=1∑n∣xi∣2)
参考